
MPI - Lab
Hello world
The aim of this exercise is to discover the MPI compilation and deployment chain.
- Initialize MPI
- Get the MPI rank of the current process
- Get the number of MPI ranks
- Get the name of the machine running the current process (see man gethostname)
- Finalisez MPI
- Compile it with mpicc and run it with mpirun on one or several machines
- Remainder on mpirun:
- -n <X> specifies the number of MPI ranks
- -f specifies the machines that run the program
Modify hello.c so that messages are sorted (i.e. rank 0 prints first, then rank 1, etc.)
To do this, each rank N waits until rank N-1 prints message N-1, then it prints message N, and then notifies process N+1.
You should get something like this:
Parallelizing an application
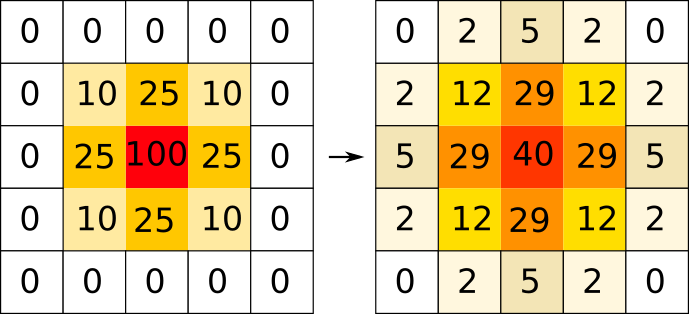
L'application stencil compute a 2D diffusion (a kind of heat equation). A 2D matrix contains values (eg. the temperature of a point in space), and each iteration computes a 5-points stencil: for each point (i,j), we compute
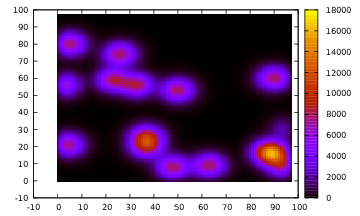
The program generates a random number of "hot points", computes several iterations, and write the result in result.dat. This result can be visualize with plot.gp (you may need to install GNUplot):
The goal of this exercise it to parallelize this application with MPI. To simplify, each MPI rank processes a N x N matrix, and computes values from Vk+1(1,1) to Vk+1(N-2,N-2) based on Vk(0,0) to V(N-1, N-1).
- After each iteration, the MPI process r sends line 1 of cur_step to rank r-1, and line N-2 of cur_step to rank r+1
- After each iteration, the MPI process r receives the line sent by r-1, stores it in next_step[0], and receives the line sent by r+1 and store it in next_step[N-1]
- At the end of the program, each rank sends its matrix to rank 0 so that it can write the result in a write.
Non-blocking communication
Insteaf of computing all the points of the matrix, and then send some lines to the neihghbours, we want to use non-blocking communication in order to "hide" the cost of communication. We first compute the lines to be sent, start communication, and compute the remaining lines, before waiting for the end of the communication.
Modify your program to implement this algorithm.
