
MPI - Travaux Pratiques
Hello world
Le but de cet exercice est de découvrir la chaine de compilation et de déploiement de MPI.
- Initialisez MPI
- Récupérez le rang MPI du processus courant
- Récupérez le nombre de processus MPI
- Récupérez le nom de la machine sur laquelle s'exécute le processus (cf man gethostname)
- Finalisez MPI
- Compilez-le et exécutez-le sur une ou plusieurs machines
- Rappel sur mpirun:
- -n <X> permet de controler le nombre de processus créés
- -f spécifie les machines sur lesquelles lancer les processus
Modifiez le programme hello.c afin que les affichages soient ordonnés (ie. le rang 0 affiche en premier, puis le rang 1, etc.)
Pour cela, chaque rang N attend que le rang N-1 ait affiché son message, affiche son message, puis notifie le processus N+1.
Vous devriez obtenir un affichage ressemblant à:
Paralléliser une application
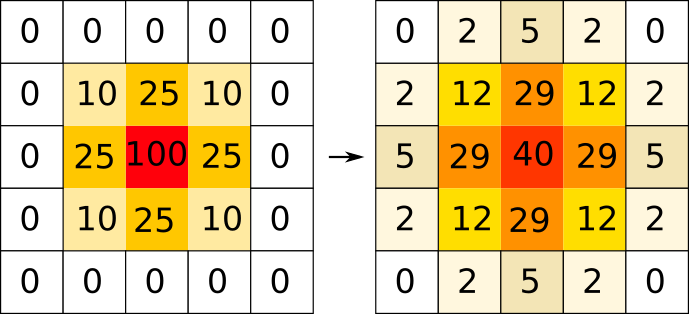
L'application stencil calcule une diffusion 2D (du type équation de la chaleur). Une matrice contient des valeurs (eg. la température d'un point de l'espace), et à chaque itération un stencil à 5 points est appliqué: pour chaque point (i,j), on calcule
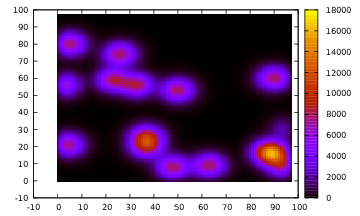
Le programme génère un nombre aléatoire de "points chauds", calcule plusieurs itérations et écrit le résultat dans le fichier result.dat. Ce résultat peut être visualisé avec le script plot.gp (qui nécessite le logiciel GNUplot):
Le but de l'exercice est de paralléliser l'application avec MPI. Afin de simplifier la mise en oeuvre, chaque rang MPI manipule une matrice de taille N x N et calcule les valeurs de Vk+1(1,1) à Vk+1(N-2,N-2) à partir des valeurs de Vk(0,0) à V(N-1, N-1).
- Après chaque itération le processus de rang MPI rank envoie la ligne 1 de cur_step au rang rank-1 et la ligne N-2 de cur_step au rang rank+1
- Après chaque itération, le processus de rang MPI rank reçoit la ligne envoyée par rank-1 et la stocke dans next_step[0], et reçoit la ligne envoyée par rank+1 et la stocke dans next_step[N-1]
- À la fin du programme, chaque processus envoie sa matrice au processus 0 afin d'écrire le résultat dans un fichier.
Communications non-bloquantes
Au lieu de calculer l'ensemble des points d'une matrice, puis envoyer certaines lignes aux voisins, on souhaite utiliser des communications non bloquantes afin de "cacher" le coût des communications: en calculant en premier les lignes à envoyer, on peut démarrer les communications, puis calculer les lignes restantes, avant d'attendre la fin des communications.
Modifiez votre programme afin d'implémenter cet algorithme.
