
Software efficiency lab#
Introduction#
In this lab, we provide you with the MyCompany Java application for managing all the data of a retail company selling and shipping products to customers all over the world.
Unfortunately, the version you have at your disposal has many shortcomings and is extremely energy consuming, so you will try, step by step, to improve its performance. This will be done by answering the following 4 questions, in order as there is a dependence between the questions:
What is the most efficient sorting algorithm (among
selectionSort,bubbleSort,insertionSort,quickSort,mergeSort)?How to extract data from a database and write them in a file efficiently?
How do SQL queries perfom compared to a Java program that reads from a local file?
How efficient is SQL for complex queries?
Note
Reminder: You will use the JoularJX tool that you have discovered in the previous lab.
For more information on JoularJX:
Initializations#
Create the ENV4101 directory (if it does not already exist) and go to that directory.
mkdir -p $HOME/ENV4101
cd $HOME/ENV4101
Activate the python environment#
In all the terminals used for this lab, activate the pythonenv environment:
source $HOME/pythonenv/bin/activate
as described on the python installation page: Installations Python
Get the code#
Get the code for this lab (click on the mouse right button) and store it in your ENV4101 directory:
or, alternatively, you can copy the following command on your terminal:
wget https://www-inf.telecom-sudparis.eu/COURS/cen/Mesures/SoftwareEfficiencyLab.zip
Unzip the code
unzip SoftwareEfficiencyLab.zip
Go to the SoftwareEfficiencyLab directory.
cd SoftwareEfficiencyLab/
Import the project in Eclipse#
Launch the Eclipse IDE (command
eclipse-java &in the lab room)File\(\leadsto\)Import\(\leadsto\)Maven\(\leadsto\)Existing Maven Projectthen click onNextSelect your ENV4101 directory, choose
SoftwareEfficiencyLaband click onOpenSelect the
pom.xmlfile and Click onFinish.
You will see the sql_manager project in your list of projects.
In the src/main/java directory, you will find the ecolog_tsp_uppa.sql_manager package containing the sources for which you are going to improve the energy efficiency.
Compile the code#
In a terminal, use the maven tool to compile the software with the following command:
mvn clean install
Important
NB: During this lab, after each modification of the code, you will have to use mvn clean install in the SoftwareEfficeincyLab directory in order to compile the code.
cd ..; mvn clean install; cd scripts
If you wish, you can add at the beginning of the scripts/main.sh script (on the second line) the following command (the compilation will take place each time you launch a script.
(cd ..; mvn clean install)
NB: With the parentheses, the cd and mvn are executed in a subshell. It implies that the change of directory is effective only for the mvn compilation command. The sequel of the bash script is executed with no change in the directory.
Overview of the provided software#
Overview of the SQL database#
The MyCompany Java application does some requests to a database coming from the Northwind MySQL sample database.
Northwind is a fictional small company. The database contains information on customers, products, orders, suppliers, shipping and employees. Its size is about 4.25 MB.
You can find below the UML class diagram representing this database and some elements on the number of elements it contains.
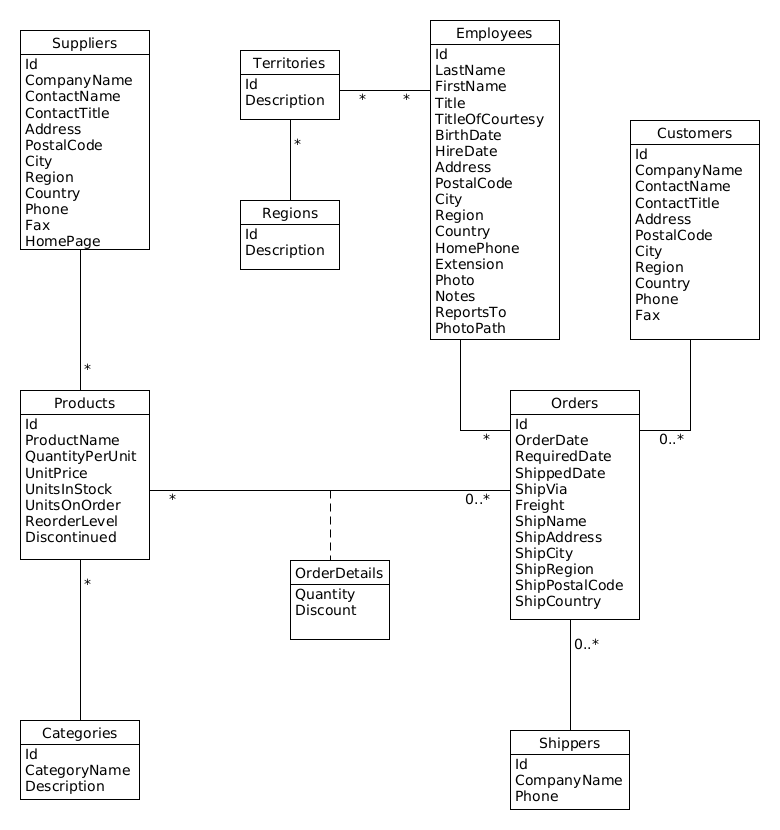
UML class diagram#
The database contains some fictional data for 91 Customers, 77 Products of 8 Categories, 29 Suppliers, 9 Employees, 6 100 Orders and 209 826 OrderDetails (order lines: one order concern several products, for each product, one OrderDetails line).
Overview of the Java Classes#
The data retrieved from SQL queries are stored in a Java object of type List<List<String>>, i.e. a matrix whose first line contains the names of the columns while the following lines contain the retrieved data.
For example, the query:
SELECT
Id,
ProductName
FROM
Products
LIMIT 3
obtains the table:
Id |
ProductName |
|---|---|
1 |
Chai |
2 |
Chang |
3 |
Aniseed Syrup |
In the MyCompany Java application, the table will be a List<List<String>> list object:
mylist = [
["Id", "ProductName"], // Columns names
["1", "Chai"], // Row 1
["2", "Chang"], // Row 2
["3", "Aniseed Syrup"] // Row 3
]
Main.java#
It is this class that you will execute to launch the MyCompany Java application over the questions.
The Main.java file is composed of the main() method and a set of other methods. The main() method parses the input arguments and executes the method corresponding to the question number given in these arguments. This latter method will be launched several times in order for JoularJX to provide results even if a single execution of this method would be too fast.
SQLManager.java#
This class contains methods that interact with the database.
Click to see all this class methods
Method |
Description |
Returned object |
|---|---|---|
|
Class constructor |
|
|
Create a connection with the SQL database |
|
|
Close the connection with the SQL database |
|
|
Execute the SQL query in parameter |
|
|
Retrieve rows of data from SQL database and store them in a table |
|
|
Sort table data by a column in natural order |
|
|
Write the table to a csv file |
|
|
Create a table from a csv file |
|
|
Filter the list to keep only the rows respecting |
|
|
Print nbRows from list to stdout |
|
Parameters.java#
This class simply loads parameters from the SQLManager.properties file. These parameters are mainly used to connect to the SQL database.
Sorts.java#
This class sorts the tables (which will be in the form of List<List<String>> objects as described earlier) according to a column in the natural order.
5 different algorithms are implemented. We summarize them here with their time-complexity for Lists. We recall that Lists have a time-complexity of \(O(1)\) for List.get(int) and List.set(int, Object), that is for accessing and swapping objects.
Method |
Best-case time-complexity |
Average time-complexity |
Worst-case time-complexity |
|---|---|---|---|
selectionSort() |
\(O(n^2)\) |
\(O(n^2)\) |
\(O(n^2)\) |
bubbleSort() |
\(O(n)\) |
\(O(n^2)\) |
\(O(n^2)\) |
insertionSort() |
\(O(n)\) |
\(O(n^2)\) |
\(O(n^2)\) |
quickSort() |
\(O(n\log(n))\) |
\(O(n\log(n))\) |
\(O(n^2)\) |
mergeSort() |
\(O(n\log(n))\) |
\(O(n\log(n))\) |
\(O(n\log(n))\) |
Script to run the application#
To launch the application with JoularJX, go to the scripts folder:
cd scripts
In the following questions, you will have to run commands of the form:
bash main.sh <number_of_times_to_launch> <question_number> <question_argument>
The higher number_of_times_to_launch is, the more times a method is launched, and the more accurate are the computed means and standard deviations. We suggest this number to be between 3 and 5 during this lab, but it depends on the speed of the device.
The question_number argument corresponds to the question number (1 to 4) and question_argument is required only in questions 1 to 3, and not used for question 4.
Concerning the JoularJX energy analyzer tool (cf. the Discover Joular JX lab), we filter the methods of the ecolog_tsp_uppa.sql_manager
package.
Fur this purpose, the config.properties file contains the line:
filter-method-names=ecolog_tsp_uppa.sql_manager
Delivery at the end of the lab#
Important
At the end of the lab, you will provide your results in moodle through:
A list of good practices that you have learnt from this lab to gain energy in software.
A synthesis of your results
A zip of your modified Code
Each time you make an experiment, you have to fill the Questionnaire. With some of the following elements
Description of the elements:
Name |
Description |
|
|---|---|---|
A |
Question |
Question number from (1 to 4.2) |
B |
Limite sur |
What is the limit argument about (Nb Orders or Nb lines to filter or /) (only for Q 1 to 3) |
C |
Limite Valeur |
Value of the limit provided in argument (only for Q 1 to 3) |
D |
nb Orders |
Nb |
E |
nb OrdersDetails |
Nb |
F |
Graph name |
png file name (you should be able to view the figure later on if needed); you can copy this name, it is given at the end of the script |
G |
Méthode estimée |
Method for which you measure the energy consumption (probably the most consuming one) |
H |
Méthode Conso (J) |
Measured Method Energy Consumption |
I |
Total Conso (J) |
Process Total energy consumption (as written at the top of the graph) |
- |
———— |
———————————- |
Question 1 - Sorting#
In this question, you will test the program with a query concerning the Orders table. It will simply retrieve orders with their lines corresponding to OrderDetails, sort them by their OrderDate and save them in a csv file.
For this test, in order to limit the execution time, we limit the number of order lines to import and sort. The quickest SQL request for this is the following one:
As odd as it may seem, it is the quickest way to have what we want:
SELECT
*
FROM
Orders o
JOIN OrderDetails od ON
od.OrderId = o.Id
WHERE
o.Id NOT IN(
SELECT
Id
FROM
(
SELECT
Id
FROM
Orders
# With MySQL, we need LIMIT to use OFFSET, so we take a high limit
LIMIT 999999999 OFFSET n
# n is the max number of Orders that we want
) AS temp
)
The Main.retrieveSomeOrders() method has been written in order to execute this query.
Selection sort#
The sort currently applied in the code is the selection sort.
The database contains 6 110 orders and a total of 209 826 lines (OrderDetails) in these orders.
First run the program to retrieve 600 orders only with the command:
bash main.sh 3 1 600 # Launch 3 times the 1st question with 600 Orders
# About 10 s per execution, so 30 s in total
A graph summarizing the consumption by method is created in the scripts/results/question_1/xxx/xx/filtered/ folder.
As you see, the main consumption comes from the selectionSort() method that has to sort about 1575 rows of OrderDetails coming from 600 Orders .
Important
Each time you make an experiment, you have to fill the questionnaire.
Experiment with other sort algorithms#
See the Sorts.java paragraph, which recalls sorting algorithms complexity and Catalog where different slow and quick sort algorithms energy consumption are provided.
These algorithms are implemented in the Sorts class. Choose a sort algorithm and perfom some testing as follows.
In the sortRows() method of the SQLManager class (see file SQLManager.java and look for TODO Question 1), replace the call to Sorts.selectionSort() with one of the following methods:
Sorts.bubbleSort()Sorts.insertionSort()Sorts.quickSort()Sorts.mergeSort()
Recompile the code (with mvn clean install in the SoftwareEfficiencyLab directory)
And launch bash main.sh 3 1 600 (in the scripts directory).
Note
If you have this message No result in filtered methods, either there is no filter or the filtered methods duration may be too short it means that the new sorting algorithm is so efficient that its consumption is not recorded. Thus you can increase the numbers of selected Orders
Increase the number of orders to more than 600 and see the highest number you can reach while still having good performances. NB: You should be able to reach 2000 orders in a reasonable execution time (~1mn).
Note
With 2000 orders, what is the most energy consuming method?
Important
You should remark that above a given number of rows, the quickSort method is inefficient. Indeed, merge sort is more efficient and works faster than quick sort in case of larger array size or datasets.
Whereas
Quick sort is more efficient and works faster than merge sort in case of smaller array size or datasets.
As we have a large number of OrderDetails rows, the mergeSort is the method that should be selected.
Keep this choice for the sequel of the lab.
Question 2 - Extract data and write in a file#
2.1 Introduction and preliminary experiment#
We are now querying all the 6 110 orders present in the database. So we remove the limit on the number of orders and write a very simple query:
SELECT *
FROM Orders
JOIN OrderDetails ON OrderDetails.OrderId = Orders.Id
The Main.retrieveOrders() method has been written in order to execute this query, sort the results (whith the merge sorting algorithm) and write it in a csv file.
However, the SQLManager.writeAsCsv() method takes much time. So we still need a limit on the max number of lines to be written in a file. To launch Main.retrieveOrders() with this limit, we give it as an argument in a command of the form:
bash main.sh 3 2 number_lines_to_write # Launch 3 times the 2nd question with a limit on the number of lines to write
NB: Without the number_lines_to_write argument, all lines (more than 200 000) will be written.
We first suggest that you test the program with 15 000 lines by running the command:
bash main.sh 3 2 15000 # Launch 3 times the 2nd question with 15 000 lines to be written
A graph summarizing the consumption by method is created in the scripts/results folder.
2.2 SQL Query#
Before examining the SQLManager.writeAsCsv() method, we can see that the execution of the query in the SQLManager.executeQuery() method is taking quite a lot of time. Why?
You need help
The volume of transfered data from the database has an impact on the consumption. If we transfer all the data, we transfer about 32MB. With a SELECT *, for each line, we have the following information: Orders.Id, Orders.CustomerId, Orders.EmployeeId, Orders.OrderDate, Orders.RequiredDate, Orders.ShippedDate, Orders.ShipVia, Orders.Freight, Orders.ShipName, Orders.ShipAddress, Orders.ShipCity, Orders.ShipRegion, Orders.ShipPostalCode, Orders.ShipCountry, OrderDetails.Id, OrderDetails.OrderId, OrderDetails.ProductId, OrderDetails.UnitPrice, OrderDetails.Quantity, OrderDetails.Discount
The volume of transfered data may be drastically reduced if we collect only the necessary columns.
In fact, for this question, we only need to store the following columns in a file:
Orders.Id,
Orders.CustomerId,
Orders.EmployeeId,
Orders.OrderDate,
Orders.RequiredDate,
Orders.ShippedDate,
OrderDetails.ProductId,
OrderDetails.Quantity,
OrderDetails.Discount
What do you suggest to reduce the time of the execution of the query in the Main.retrieveOrders() method?
Need help?
In the retrieveOrders() method of the Main class, replace the `sqlQuery` stringfinal String sqlQuery = """
SELECT *
FROM
Orders
JOIN OrderDetails ON OrderDetails.OrderId = Orders.Id
""";
with:
final String sqlQuery = """
SELECT
Orders.Id,
Orders.CustomerId,
Orders.EmployeeId,
Orders.OrderDate,
Orders.RequiredDate,
Orders.ShippedDate,
OrderDetails.ProductId,
OrderDetails.Quantity,
OrderDetails.Discount
FROM
Orders
JOIN OrderDetails ON OrderDetails.OrderId = Orders.Id
""";
Compile the code again and relaunch the following command again.
bash main.sh 3 2 15000 # Launch 3 times the 2nd question with 15 000 lines to write
With this modification, are you able to retrieve more lines ? What is now the the most consuming method ?
2.3 Writing in a file#
Warning
For some reason, the writing part can take much more time than it should (like 30 s instead of 5 s). Do not hesitate to relaunch the Java application in those cases.
Now that we have reduced the number of columns to retrieve, let us see the limits of the writeAsCsv() method.
We suggest you to try with 30 000 lines and then 60 000 lines:
bash main.sh 3 2 30000 # Launch the 2nd question with 30 000 lines to be written
bash main.sh 3 2 60000 # 60 000 lines
It seems that the consumption of the writeAsCsv() method (in the SQLManager class) is not linear on the number of lines to write but it could be quadratic on it.
Let us see this method.
At first sight, we see that this method writes character by character, which could not be worse!
Let us first replace
final String column = row.get(j);
for (int k = 0; k < column.length(); k++) {
char c = column.charAt(k);
csvOutputFile.write(c);
}
by
final String column = row.get(j);
csvOutputFile.write(column);
Compile the code and relaunch the command:
bash main.sh 3 2 60000 # 60 000 lines
Did you save energy by doing this? Does it seem to be enough?
With what we just saw, it seems that the less we call the Writer.write() method, the less energy we use.
For now, the method only writes column by column. We could also try to write row by row. In fact, we do not know exactly where the consumption comes from!
Hopefully, JoularJX can help us: since it is able to measure the consumption at level of methods, we can therefore replace portions of code by some methods.
In the SQLManager class, create a
String buildString()and avoid writeInFile(FileWriter file, String s)methods and move the corresponding portion of code.
Need help?
Replace the writeAsCsv method lines by those three methods :
public static void writeAsCsv(final List<List<String>> rows, final String filePath) throws IOException {
final long start = System.currentTimeMillis();
System.out.println("writing " + Integer.toString(rows.size() - 1) + " rows at " + filePath);
try (FileWriter csvOutputFile = new FileWriter(filePath)) {
for (int i = 0; i < rows.size(); i++) {
final List<String> row = rows.get(i);
String line = buildString(row);
writeInFile(csvOutputFile, line);
}
}
final long end = System.currentTimeMillis();
System.out.println("file created in: " + (end - start) + "ms");
}
private static void writeInFile(final FileWriter file, final String s) throws IOException {
file.write(s);
}
private static String buildString(final List<String> row) {
String line = "";
for (int j = 0; j < row.size(); j++) {
String column = row.get(j);
if (j == row.size() - 1) { // Last column
line += column + "\n";
} else {
line += column + ",";
}
}
return line;
}
Now, when we launch bash main.sh 3 2 60000, the graph shows the actual consumption of the creation of the strings and their writing process.
What do you notice? Which line seems to be responsible of such a big consumption of the writeAsCsv() method? How to be sure?
Why is this line so consuming? How to modify writeAsCsv() for making it much less consuming?
Tip
Have a look on the type of List implementation used by the retrieveData() method. And remember a result found in the Discover JoularJX lab.
Need help ?
The
buildString()andwriteInFile()are not big consumers compared to the other methods.Since in the looping structure there is only the
final List<String> row = rows.get(i)that remains, it should be the responsible.Indeed the List implementation used by the
retrieveData()method is a LinkedList, and you have seen at the previous lab that accessing to elements in a LinkedList is energy consumingTo be sure, we could create a function
List<String> get(List<List<String>> rows)like we did forbuildString()but it is not necessary since it is the only line in the loop inwriteAsCsv()that calls a function (List.get()) where the graph does not show its energy consumption.LinkedList.get()has a time complexity of \(O(n)\), included in a loop on the number of elements, it results in a \(O(n^{2})\) time complexity.
Solution
The following code is a solution where we use an enhanced for loop. With this loop, we avoid calling the LinkedList.get() method. As a consequence the time complexity returns to \(O(n)\). Test the result.
public static void writeAsCsv(final List<List<String>> rows, final String filePath) throws IOException {
final long start = System.currentTimeMillis();
System.out.println("writing " + Integer.toString(rows.size() - 1) + " rows at " + filePath);
try (FileWriter csvOutputFile = new FileWriter(filePath)) {
for (final List<String> row : rows) {
final String line = buildString(row);
writeInFile(csvOutputFile, line);
}
}
final long end = System.currentTimeMillis();
System.out.println("file created in: " + (end - start) + "ms");
}
Note
Now you should be able to launch bash main.sh 1 2 with no limit on the number of lines and without much energy consumption. May be it is so low that you don’t have any graph.
In any case, we can conclude that
enhanced for loop is very efficient to scroll a Linked list
we have created the
csv_folder/orders.csvfile with the total number of order lines present in the database, that are 209 826 lines. you can verify withwc -l csv_folder/orders.csv(this command provides as a result the number of lines of this file).
Question 3 - SQL remote query versus read a local csv file#
3.1 Introduction and preliminary experiment#
Now that the MyCompany Java application seems to be working, we would like to list the orders that have not been delivered (Orders.ShippedDate IS NULL) and write them to a csv file. This file should be sorted from the Order with the earliest required date (Orders.RequiredDate) to the one with the latest required date.
A Main.retrieveOrdersToShip() function has been written but it has some shortcomings.
Once again, for testing this method, we will put a limit when launching the MyCompany Java application. Therefore, to launch Main.retrieveOrdersToShip(), you will use a command of the form:
bash main.sh 3 3 number_lines_to_filter # Launch 3 times the 3rd question with a limit on the number of rows to be filtered
Without the number_lines_to_filter argument, all the lines will be extracted.
Warning
Make sure that you previously executed the main.sh script for question 2 and that it has created the full csv_folder/orders.csv file.
This is done with command: bash main.sh 1 2 (with no other argument). Verify that the csv file contains 209827 lines with the following command.
$ wc -l csv_folder/orders.csv
That should give the following result
209827 csv_folder/orders.csv
3.2 Preparation to use Local or server data#
Since we created, in the question 2, a csv file containing all the Orders with their OrderDetails, we are wondering whether it is better to read from the local csv file or to let the SQL server process the data.
To compare these two solutions, we will use two methods: one local version retrieveOrdersToShipLocal() and one server version retrieveOrdersToShipServer().
You will then have to select which one to use in the retrieveOrdersToShip() method.
First replace retrieveOrdersToShip() by the following code:
// The method in which we choose between Local and Server
public static List<List<String>> retrieveOrdersToShip(final String pathToWriteCsv, final int nbRowsToFilter) throws SQLException, IOException {
// Choose one line of the following 2 lines and comment the other one
return retrieveOrdersToShipLocal(pathToWriteCsv, nbRowsToFilter);
//return retrieveOrdersToShipServer(pathToWriteCsv, nbRowsToFilter);
}
3.3 Local#
The code to copy in Main.java: Local version - Method retrieveOrdersToShipLocal
// Local version
public static List<List<String>> retrieveOrdersToShipLocal(final String pathToWriteCsv, final int nbRowsToFilter) throws SQLException, IOException {
// Retrieve orders by calling method SQLManager.readFromCsv()
final List<List<String>> rows = SQLManager.readFromCsv(ORDERS_CSV);
// Limit if needed
if (nbRowsToFilter > 0) {
rows.subList(nbRowsToFilter + 1, rows.size()).clear();
}
// Filter the rows
SQLManager.filterLike(rows, "Orders.ShippedDate", "null"); // Keep the orders whose ShippedDate is null
// Sort the rows
SQLManager.sortRows(rows, "Orders.RequiredDate");
// Store the rows in a csv file
SQLManager.writeAsCsv(rows, pathToWriteCsv);
return rows;
}
This code calls the
SQLManager.readFromCsv()method to read from theORDERS_CSVfile and creates a list of rows. Then, it uses thefilterLike()method to filter on the condition thatOrders.ShippedDateis null.
Launch with bash main.sh 3 3 50000 till bash main.sh 3 3 100000 to determin the number of lines where you get some results on your device.
The main consuming methods are readFromCsv() and filterLike() of the SQLManager class. We will now try to improve them.
3.3.1 Improve SQLManager.readFromCsv()#
How does this method read the csv file and create rows?
And why does it seem not to be efficient?
Need help?
The method reads the file line by line to create a row with each line, which —for now— seems relevant, but it then reads character by character the lines to append them to a column.
When the character is a comma “,”, it passes to another column and add the last one to the current row.
When the character is the last one, the current column is stored in the current row. The latter is then appended to the rows list and a new line is processed.
Of course, reading character by character is not efficient when we can manipulate Strings.
We can now create the row more efficiently:
By using
line.split(String delimiter), create the array of the columns.
Then, by usingArrays.asList(Object[])you can create a fixed-size List. You will have to create a new ArrayList or LinkedList by putting the fixed-size array as the constructor parameter.
Solution
public static List<List<String>> readFromCsv(final String filePath) throws IOException {
final long start = System.currentTimeMillis();
System.out.println("reading rows from " + filePath);
final List<List<String>> rows = new LinkedList<>();
try (BufferedReader br = new BufferedReader(new FileReader(filePath))) {
String line;
while ((line = br.readLine()) != null) {
final String[] values = line.split(",");
final List<String> row = new LinkedList<>(Arrays.asList(values));
rows.add(row);
}
}
final long end = System.currentTimeMillis();
System.out.println("file readed in: " + (end - start) + "ms");
System.out.println(Integer.toString(rows.size() - 1) + " rows loaded");
return rows;
}
3.3.2 Improve SQLManager.filterLike()#
How does this method filter the rows list?
And why does it seem not to be efficient?
In a first loop over the list, it stores the indexes of the rows to remove. Then, in a second loop, it removes them.
It could be much more efficient to create a new list of rows by selecting the rows to be kept instead of removed.
Modify the
SQLManager.filterLike()method in which you :
Create a new List. Append to it the row with the columnNames (which is the first row)
Add the rows that verify the condition to the new list
Clear the original list and use
rows.addAll(newList)(to respect thevoidreturn and to keep the class of the List, you cannot just return the new list)
Solution
/**
* Filters the rows with a "WHERE columnWhere LIKE condition"-condition like.
* <br>
* Or "WHERE columnWhere = condition". <br>
* Or "WHERE columnWhere IS NULL". <br>
* This method creates a new list with the rows that respect the condition and
* replace the original list by the new one.
*
* @param rows
* @param columnWhere
* @param condition For the "LIKE" or "=" argument. Put "null" if you want to
* keep rows WHERE columnWhere IS NULL.
*/
public static void filterLike(final List<List<String>> rows, final String columnWhere,
final String condition) {
final long start = System.currentTimeMillis();
System.out.println("filter " + Integer.toString(rows.size() - 1) + " rows");
final List<String> columnNames = rows.get(0);
final int index = columnNames.indexOf(columnWhere);
if (index == -1) {
System.err.println("to search on a columnName that does not exist in "
+ Arrays.toString(columnNames.toArray()));
return;
}
final List<List<String>> newList = new ArrayList<>();
newList.add(rows.get(0)); // column names
for (List<String> row : rows.subList(1, rows.size())) {
if (row.get(index).equals(condition)) {
newList.add(row);
}
}
rows.clear();
rows.addAll(newList);
final long end = System.currentTimeMillis();
System.out.println("rows filtered in: " + (end - start) + "ms");
System.out.println(Integer.toString(rows.size() - 1) + " rows remains");
}
After fixing these 2 methods, you should be able to launch bash main.sh 3 3 60000 and obtain better results.
Warning
If the execution of the program is too fast and does not allow JoularJX to give results, change the upper bound in the for loop calling for retrieveOrdersToShip(), which is in the “case 3” part of Main.main(). Try with i < 10 for example.
3.4 Server#
Note the total consumption of the local results (read in a csv file the results obtained from a previous query) and try the version with a remote call to the SQL server to obtain the values and compare the consumptions.
Change the line of
Main.retrieveOrdersToShip()to returnretrieveOrdersToShipServer(pathToWriteCsv, nbRowsToFilter)instead of the local version.
Modify theMain.retrieveOrdersToShipServer()method in order to have only one query and save the resulting rows in a csv file.
Code to copy in Main.java: Server version - Method retrieveOrdersToShipServer
public static List<List<String>> retrieveOrdersToShipServer(final String pathToWriteCsv, final int nbRowsToFilter)
throws SQLException, IOException {
final String sqlQuery = """
SELECT
Orders.Id,
Orders.CustomerId,
Orders.EmployeeId,
Orders.OrderDate,
Orders.RequiredDate,
Orders.ShippedDate,
OrderDetails.ProductId,
OrderDetails.Quantity,
OrderDetails.Discount
FROM
Orders
JOIN OrderDetails ON OrderDetails.OrderId = Orders.Id
WHERE Orders.ShippedDate IS NULL
# ORDER BY # 2 Lines initially in comments
# Orders.RequiredDate; # to compare with a call to SQLManager.sortRows()
""";
// Connection to the DataBase
final SQLManager sqlm = new SQLManager(SQL_ENGINE, DB_PATH, USER, PASSWORD);
// Execute the query
final ResultSet queryResultSet = sqlm.executeQuery(sqlQuery);
// Retrieve the rows as a result from the query
final List<List<String>> rows = sqlm.retrieveData(queryResultSet);
// Comment the call to SQLManager.sortRows()
// if the above sqlQuery has an ORDER BY clause
// Sort the rows
SQLManager.sortRows(rows, "Orders.RequiredDate");
// Store the rows in a csv file
SQLManager.writeAsCsv(rows, pathToWriteCsv);
return rows;
}
See if it is better or worse by uncommenting the ORDER BY-line with “#” and commenting SQLManager.sortRows(rows, "Orders.RequiredDate");.
Conclusions
For this example, you should be able to determine which of local or server processing is the most efficient strategy.
Depending on the power of your device and on the number of rows to sort, it might be a good idea to try to sort locally instead of using ORDER BY on the MySQl server. But this needs to be experimented with your own settings.
Question 4 - Complex SQL queries#
In Question 3, we have seen that there are many undelivered Orders. We are then wondering if the manager has done their work properly or if the issue comes from not having enough employees.
We want here to have the list of the employees with their name, the number of Orders for which they were responsible, the number of orders delivered late or not delivered and the ratio of the number of late Orders to the total number of Orders. And we want them sorted by the “failure ratio”.
Take a look at the code of the Main.retrieveStatsEmployee() method.
Explanation
This method:
Fetches data from the Employees table with a first query and creates a list with their name and their id
Then, for each employee, it makes 2 queries for fetching the total number of orders and the number of late orders, calculates the “Failure Ratio” with them and insert the result in the row of the employee.
Finally, it sorts the list and writes it in a file.
4.1 Several queries#
Launch the script and fill the Questionnaire.
bash main.sh 3 4 # Launch 3 times the 4th question
4.2 SQL Query - Unity makes strength#
4.2.1 Assemble SQL queries with UNION or JOIN#
According to the obtained results, it seems that we can only have gains in power by reviewing our SQL query (executeQuery is the most energy consuming method).
First, we could reduce the number of queries to be executed by assembling the two queries (for total number of orders and late orders) into one.
Use the UNION or the JOIN clause in the “for-each employee”-loop to reduce the number of queries.
Solution
UNION Version
// For each employee
for (final List<String> employee : employees.subList(1, employees.size())) {
// Get the total number of orders
final String sqlQueryEmployeeTotalOrder = """
SELECT
COUNT(*)
FROM
Orders
WHERE Orders.EmployeeId = """ + " " + employee.get(1);
// Get the number of orders delivered late
final String sqlQueryEmployeeLateOrder = """
SELECT
COUNT(*)
FROM
Orders
WHERE (Orders.ShippedDate > Orders.RequiredDate OR Orders.shippedDate IS NULL)
AND Orders.EmployeeId = """ + " " + employee.get(1);
final String unionQuery = sqlQueryEmployeeTotalOrder + " UNION " + sqlQueryEmployeeLateOrder;
// Execute the query
final ResultSet queryResultSetEmployeeOrder = sqlmEmployees.executeQuery(unionQuery);
// Retrieve the rows as a result from the query
final List<List<String>> employeeOrder = sqlmEmployees.retrieveData(queryResultSetEmployeeOrder);
// The total number of orders is here
String totalOrder = employeeOrder.get(1).get(0);
// The number of late orders is here
String lateOrder = employeeOrder.get(2).get(0);
final String failureRatio = Double.toString(Double.parseDouble(lateOrder) / Double.parseDouble(totalOrder));
employee.add(totalOrder);
employee.add(lateOrder);
employee.add(failureRatio);
}
JOIN Version
// For each employee
for (final List<String> employee : employees.subList(1, employees.size())) {
// Get the total number of orders
final String sqlQueryEmployeeTotalOrder = """
SELECT
COUNT(*) AS `Total Orders`,
late.`Late Orders`
FROM
Orders
JOIN(
SELECT
COUNT(*) AS `Late Orders`
FROM
Orders
WHERE
(
Orders.ShippedDate > Orders.RequiredDate OR Orders.shippedDate IS NULL
) AND Orders.EmployeeId = """ + " " + employee.get(1) + " " + """
) AS late
WHERE
Orders.EmployeeId = """ + " " + employee.get(1);
// Execute the query
final ResultSet queryResultSetEmployeeOrder = sqlmEmployees.executeQuery(sqlQueryEmployeeTotalOrder);
// Retrieve the rows as a result from the query
final List<List<String>> employeeOrder = sqlmEmployees.retrieveData(queryResultSetEmployeeOrder);
// The total number of orders is here
String totalOrder = employeeOrder.get(1).get(0);
// The number of late orders is here
String lateOrder = employeeOrder.get(1).get(1);
final String failureRatio = Double.toString(Double.parseDouble(lateOrder) / Double.parseDouble(totalOrder));
employee.add(totalOrder);
employee.add(lateOrder);
employee.add(failureRatio);
}
Recompile the code and relaunch the script and see if you have gains in power.
4.2.2 Complex SQL query with Group By#
With the JOIN version, we know how to have the information we need for each employee in one row. We should therefore be able to make a single SQL query to get all the data we need.
A solution with a single SQL query in retrieveStatsEmployees()
public static List<List<String>> retrieveStatsEmployees(final String pathToWriteCsv)
throws SQLException, IOException {
final String sqlQuery = """
SELECT
Employees.FirstName,
COUNT(Orders.EmployeeId) AS `Late Orders`,
t.total AS `Total Orders`,
COUNT(Orders.EmployeeId) / t.total AS `Failure Ratio`
FROM
Orders
JOIN Employees ON Orders.EmployeeId = Employees.Id
JOIN(
SELECT
Employees.Id AS `e_id`,
COUNT(Orders.EmployeeId) AS `total`
FROM
Orders
JOIN Employees ON Orders.EmployeeId = Employees.Id
GROUP BY
Orders.EmployeeId
) AS t
ON
t.e_id = Employees.Id
WHERE
Orders.ShippedDate > Orders.RequiredDate OR Orders.ShippedDate IS NULL
GROUP BY
Orders.EmployeeId
ORDER BY # See last remark of question 3
`Failure Ratio`; # A local sort can sometimes be better
""";
// Connect to the DataBase
final SQLManager sqlm = new SQLManager(SQL_ENGINE, DB_PATH, USER, PASSWORD);
// Execute the query
final ResultSet queryResultSet = sqlm.executeQuery(sqlQuery);
// Retrieve the rows as a result from the query
final List<List<String>> rows = sqlm.retrieveData(queryResultSet);
// Sort the rows
// SQLManager.sortRows(rows, "Failure Ratio"); // See last remark of question 3
// Store the rows in a csv file
SQLManager.writeAsCsv(rows, pathToWriteCsv);
return rows;
}
Now that you have the name of the employee with the highest “failure ratio”, you can find their title in the company!
Recompile the code and relaunch the script and see if you have gains in power.
Question 4 Conclusions
Did you get any gain by
Using complex queries while reducing the number of queries ?
Lab Conclusions
Taking care while writing code may have an impact on energy consumption.
We hope you have learn some software good practices in this lab, and above all that you will continue to take care of the written code in your future software contributions for more energy efficiency !
Delivery at the end of the lab (on moodle)#
Upload the Questionnaire.txt file (individually) on moodle.
Prepare a zip file with the results and the modified code and upload it (individually) on moodle.
cd ~/ENV4101/SoftwareEfficiencyLab
mvn clean
zip -r Mesure4.zip src scripts/results