
Performance analysis
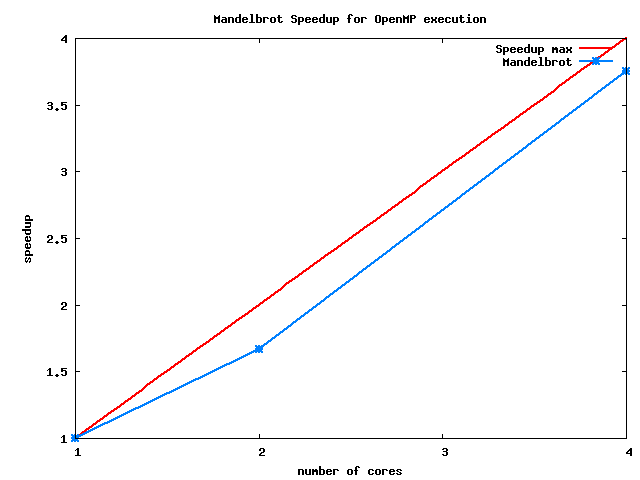
Speedup plot
- Run the mandelbrot application while varying the number of OpenMP threads
- Create a .data file that contains:
- First column: the number of threads;
- Second column: the serial execution time;
- Third column: the parallel execution time
- Examine and modify this Gnuplot file speedup.plot :
- Run the following command to generate a .png file:
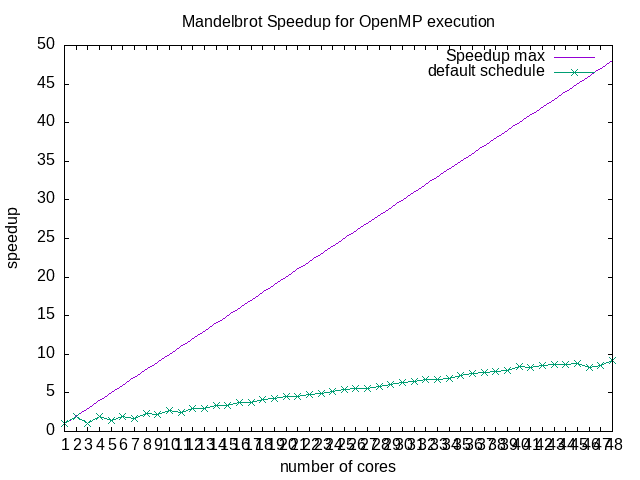
- Here's an example of output: SpeedUpMandelbrot-OpenMP.png.
To measure the performance, we can create a script file that runs the program, and generates the plot: run.sh.
Running the script on machine 3a401-13 gives the following performance measurement. By modifying the gnuplot script and running gnuplot speedup_v1.gp, we obtain the following speedup plot:
Profiling
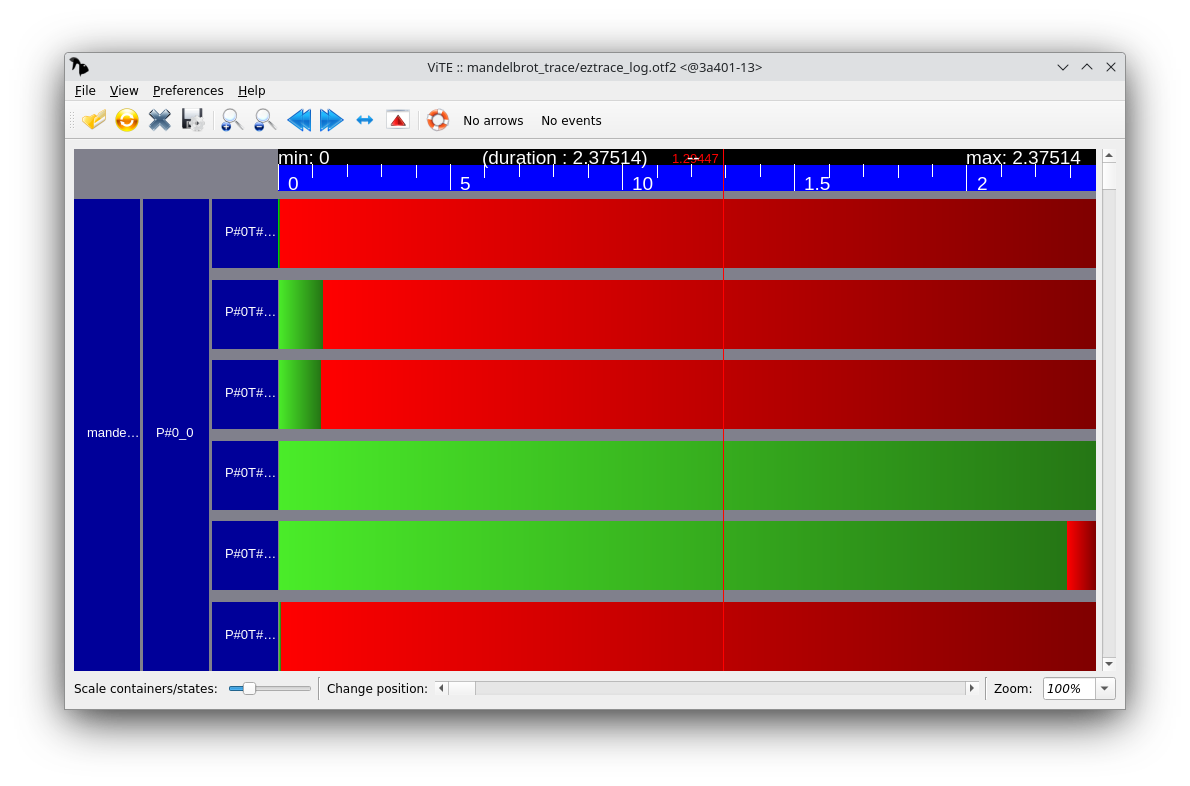
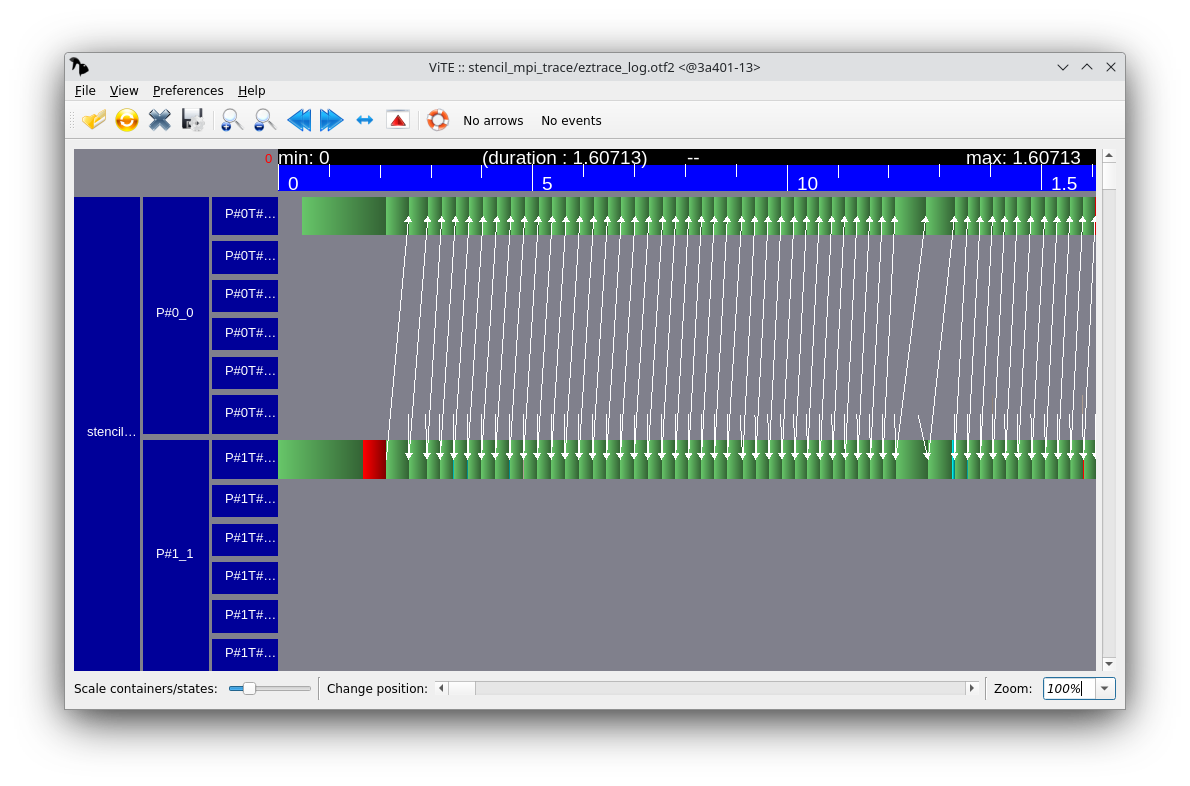
Tracing the execution of an OpenMP
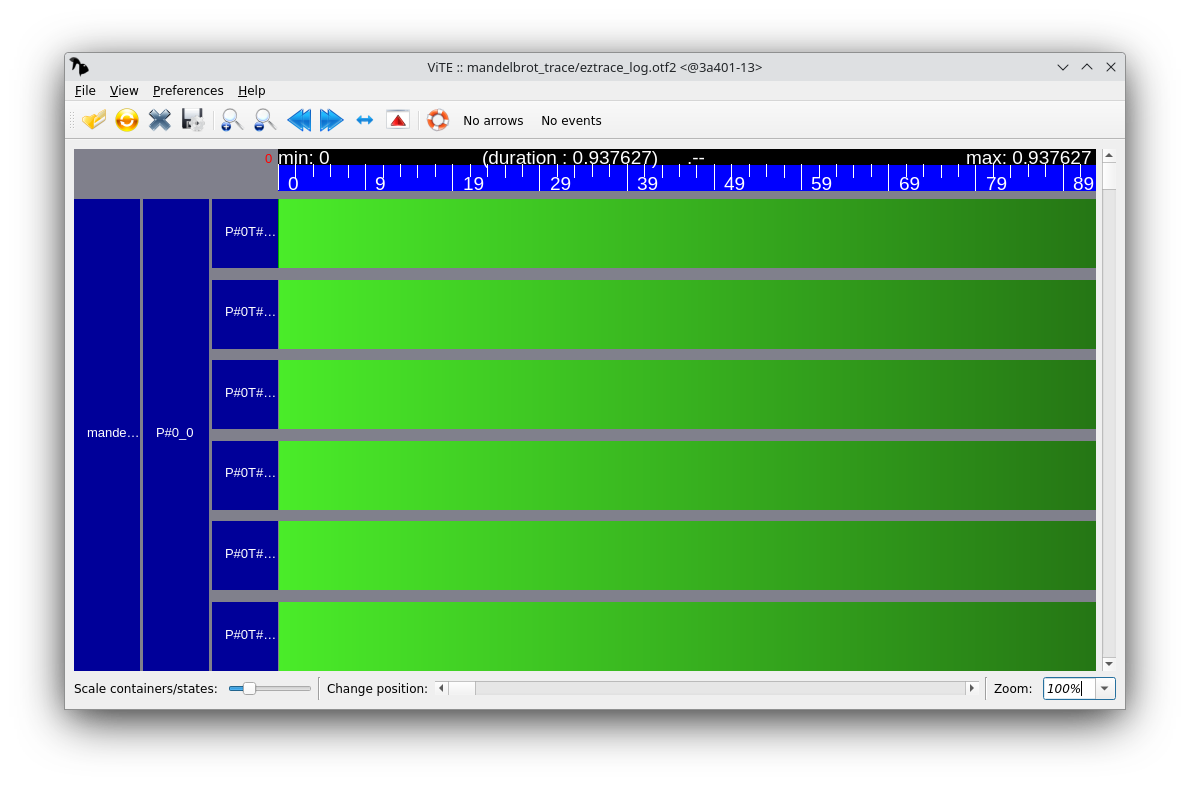
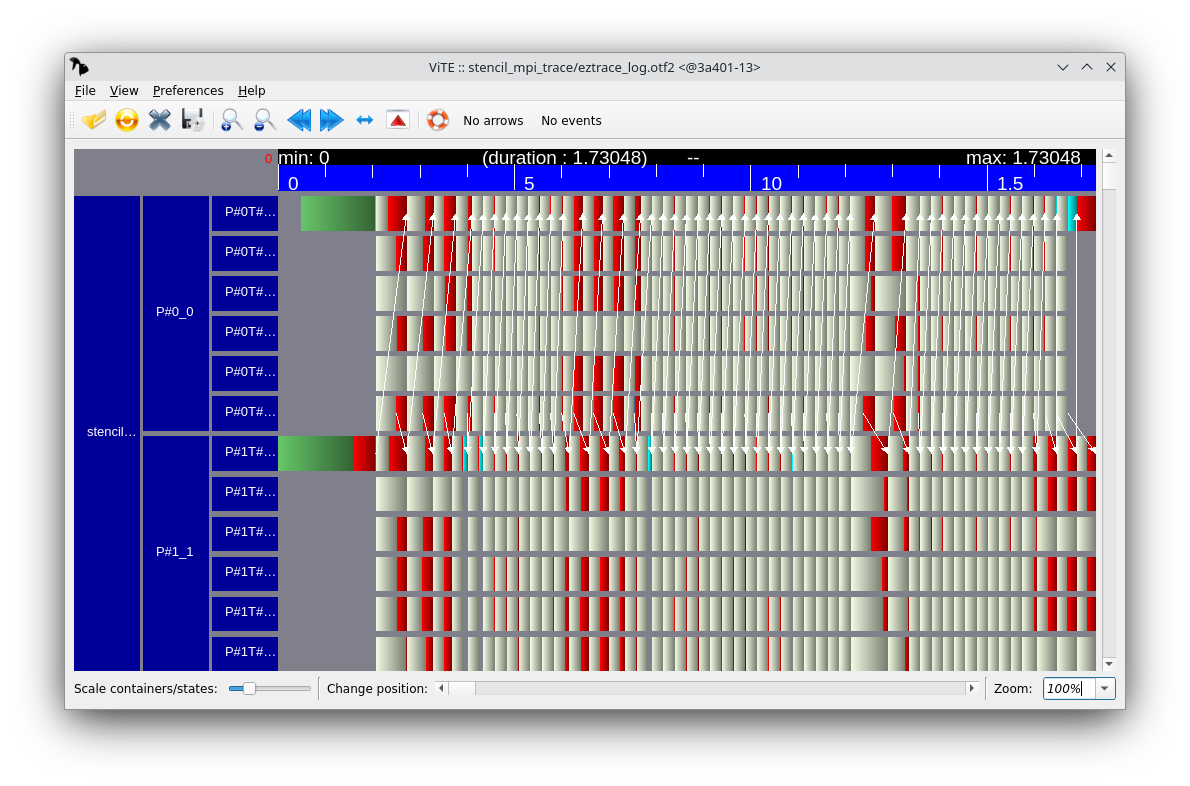
When visualizing the execution trace, you should see a load imbalance problem (this is the same problem as during the Parallel algorithmics lab). Fix this problem and generate another execution trace that shows that the load is balanced between threads.
To fix the load imbalance problem, add a schedule(dynamic) directive to the #pragma omp parallel for directive:
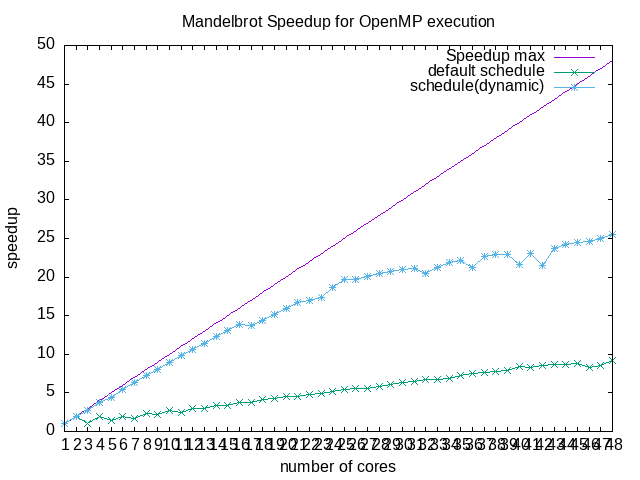
Now, run the performance measurement with a varying number of threads, and integrate the measured execution time to the speedup plot. The plot should include two lines: the original speedup plot, and the optimized speedup plot.
Tracing the execution of an MPI program

{kind=link}