
Tri fusion (∼1h10 – moyen – obligatoire)
Le tri étant décidément une réelle passion chez les informaticiens, nous allons étudier un nouvel algorithme de tri appelé l'algorithme de tri fusion (merge sort en anglais). Cet algorithme est intéressant car il peut être mis en œuvre de façon relativement efficace.
L'algorithme de tri fusion part de l'idée qu'il faut diviser pour mieux régner. Le principe est de prendre un tableau non trié et de le partitionner en deux parties à peu près égales. Ensuite, de façon récursive, l'algorithme trie le tableau de gauche et le tableau de droite. Enfin, l'algorithme fusionne les deux tableaux triés pour construire un tableau contenant tous les éléments triés. Cette opération de fusion est une opération relativement efficace car fusionner des tableaux triés est rapide en terme de temps de calcul.
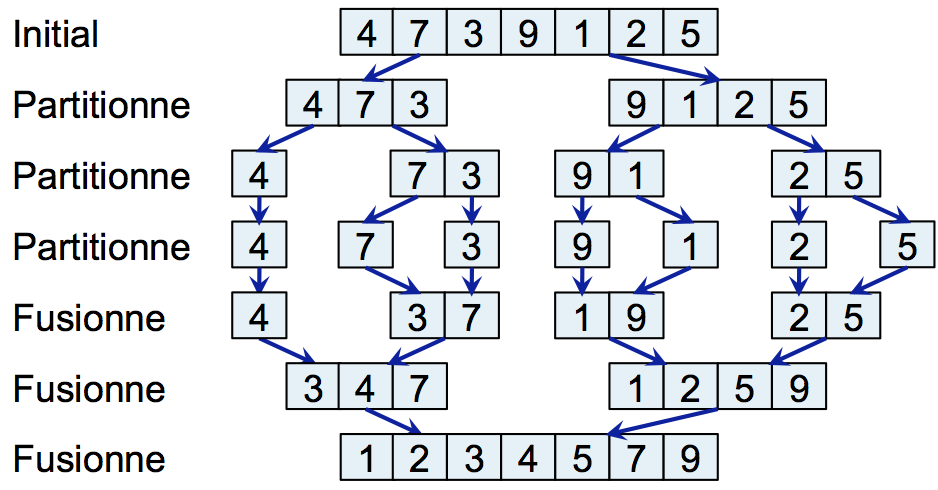
Le schéma suivant illustre le principe. De façon récursive, l'algorithme commence par partitionner les tableaux jusqu'à obtenir des tableaux de taille 1. Ce tableau de taille 1 est naturellement trié. Ensuite, l'algorithme fusionne les tableaux de façon à reconstruire la liste triée.
La mise en œuvre que nous vous proposons dans cet exercice n'est pas optimisée, mais elle a l'avantage d'être relativement simple à comprendre. Cette mise en œuvre est subdivisée en trois parties. Dans la première partie, nous écrivons la méthode qui fusionne des tableaux triés. Dans la second partie, nous écrivons la méthode qui partitionne les tableaux. Enfin, dans la troisième partie nous complétons notre programme en utilisant les deux méthodes précédentes.
Une illustration fantaisiste de l'algorithme est donnée ici.
Nous pouvons maintenant mettre en œuvre la fusion. Pour cela, vous allez écrire une nouvelle méthode nommée merge, prenant en argument deux tableaux t1 et t2 triés et renvoyant la fusion de ces deux tableaux. Le fait qu'il y ait deux méthodes merge ne pose pas de problème, car les arguments des deux méthodes sont différents, ce qui permet à Java de savoir quelle méthode on souhaite appeler en fonction des paramètres.
Nous mettons en œuvre merge de façon récursive :
- Si t1 a une taille égale à zéro, alors merge doit renvoyer t2
- Si t2 a une taille égale à zéro, alors merge doit renvoyer t1
- Si t1[0] est plus petit que ou égal à t2[0], alors merge doit renvoyer le tableau construit à partir de t1[0] et du résultat de la fusion de la partie droite de t1 avec le tableau t2. La partie droite de t1 s'obtient en appelant la méthode right et l'ajout à gauche de t1[0] s'obtient en appelant la seconde méthode merge que vous avez défini à la question précédente.
- Dans le cas inverse, il suffit d'appeler merge en inversant les rôles de t1 et t2.
Testez merge en affichant le résultat de la fusion de t1 et t2 dans la méthode main.
Les deux cas les plus couteux sont les deux derniers. On note que le dernier cas se produit au maximum n fois. L'avant-dernier cas nous donne la relation de récurrence suivante:
Où le n vient de right et int[] merge(int val, int[] tab). On appelle ensuite merge avec un élément en moins dans un des tableaux. À partir de là, nous avons:
La complexité finale de merge est donc quadratique.
- Création du tableau final de taille égale à la somme des deux tailles.
- Pour chacune des deux tableaux t0 et t1, nous conservons indice i0 et i1 nous indiquant notre position dans chaque tableau. Ces indices sont initialisés à 0 et seront incrémenté de 1 à chaque fois qu'un élément sera ajouté au tableau final.
- Tant que les deux indices ne sont pas égaux à la taille de leur tableau respectif, prendre la valeur la plus petite entre t0[i0] et t1[i1] et la rajouter au tableau final. Incrémenter la valeur de l'indice ayant amené l'ajout.
Dans cette partie, nous nous occupons de partitionner un tableau.
Nous pouvons enfin mettre en œuvre l'algorithme du tri-fusion.
- Si tab a une taille inférieure ou égale à 1, alors le tableau est déjà trié et il suffit de le renvoyer.
- Sinon, il faut appeler mergeSort sur la partie gauche de tab, puis mergeSort sur la partie droite de tab et enfin utiliser merge pour fusionner les résultats des deux appels à mergeSort.
On rappelle que :
En réalité, la complexité avec un merge efficace est , ce qui est la complexité optimale pour un algorithme de tri ! En effet, la relation de récurrence devient : Le log vient du fait que l'on divise n par deux jusqu'à obtenir un nombre inférieur à 1.
