
CI7 : À la recherche de Bilbao
L'objectif de ce TP est d'étudier les listes doublement chaînées circulaires, les tables de hachages et les génériques en Java.
Durée des exercices obligatoires : 2h30 en présentiel + 45mn en hors présentiel
- Exercice 1 : obligatoire (facile, ∼40mn)
- Exercice 2 : obligatoire (difficile, ∼1h)
- Exercice 3 : obligatoire (moyen, ∼30mn)
- Exercice 4 : obligatoire (moyen, ∼20mn)
- Exercice 5 : entraînement (moyen, ∼45mn)
- Exercice 6 : entraînement (difficile)
- Exercice 7 : entraînement (difficile)
- Exercice 8 : entraînement (difficile)
- Exercice 9 : entraînement (difficile)
Avant de pouvoir partir en vacances à Bilbao, il faut être capable de retrouver les coordonnées GPS d'une ville à partir de son nom. En effet, dans le CI4, notre application manipule directement les structures de données représentant les villes, mais notre application devrait avant être capable de retrouver ces structures de données lorsque l'utilisateur saisit des noms de villes dans l'interface.
De façon générale, une structure associant des clés à des valeurs s'appelle une table d'associations (aussi appelé dictionnaire ou encore map en anglais). Dans cet exercice, notre table d'associations associe des noms de ville (les clés) à des coordonnées GPS (les valeurs). Les tables d'associations sont omniprésentes en informatique. Ces tables sont, par exemple, utilisées par de nombreux serveurs Web comme Facebook, Google ou Amazon afin de retrouver les données associées à un utilisateur à partir de son identifiant de connexion. Vous avez même déjà mis en œuvre une table d'associations en utilisant un arbre binaire de recherche lorsque vous avez conçu la banque Lannister en CI3 : cette structure nous servait à retrouver un compte en banque (une valeur) à partir d'un nom d'utilisateur (une clé).
Dans ce TP, nous étudions une nouvelle mise en œuvre de la table d'associations : la table de hachage (hashmap en anglais). La table de hachage est une structure de données particulièrement efficace. Dans le meilleur cas, elle permet de retrouver une valeur à partir de sa clé en un temps constant (c.-à-d. Indépendamment du nombre d'éléments dans la table). Le pire cas est proportionnel au nombre d'éléments et le cas moyen est en général proportionnel à une racine nième du nombre d'éléments, où n est une constante dépendante de la mise en œuvre.
Abstraitement, une table de hachage est un tableau de taille infinie contenant des couples clés/valeurs. Le principe est d'associer un numéro unique à chaque clé. Ce numéro s'appelle le code de hachage de la clé et correspond à l'entrée à laquelle se trouve le couple clé/valeur associé à la clé dans le tableau. La figure ci-dessous, dans laquelle seules les valeurs sont représentées, illustre le précepte. À partir de la clé K, on calcule le code de hachage N qui est directement l'indice contenant le couple clé/valeur associé à la clé K dans le tableau.
Concrètement, une table de hachage ne peut pas être infinie et il est difficile de garantir que deux clés différentes auront deux codes de hachage différents. Pour cette raison, il peut arriver que plusieurs couples clé/valeur se retrouvent dans la même case du tableau. De façon à gérer ces collisions, chaque entrée du tableau stocke en fait une liste d'associations clés/valeurs secondaire. Comme présenté sur la figure ci-dessous, pour trouver la valeur associée à la clé k5, il faut d'abord calculer le code de hachage H de la clé (dans notre exemple, ce code vaut 7, la façon de calculer les codes de hachage est discuté dans l'exercice 1). Ensuite, l'entrée à laquelle se trouve la clé k5 est H modulo la taille du tableau (dans notre exemple, l'entrée est 2). Comme il peut y avoir des collisions lorsque plusieurs clés sont associées à cette entrée, l'entrée contient une liste d'association clés/valeurs. Il suffit alors de chercher k5 dans cette liste pour retrouver la valeur v5 associée à k5.
Si le tableau a une taille suffisamment grande et si la probabilité de collision entre codes de hachage est faible, les listes référencées par la table contiennent au plus une unique entrée. L'algorithme met donc un temps constant, indépendant du nombre d'éléments se trouvant dans la table de hachage, pour trouver une valeur à partir d'une clé. Dans la plupart des mises en œuvre, on a toutefois des tailles de liste égales en moyenne à une racine nième du nombre d'éléments (où n est une constante dépendante de la mise en œuvre), ce qui offre des performances très satisfaisantes.
Les identifiants de villes et les positions (∼40mn – facile – obligatoire)
Dans ce premier exercice, nous mettons en œuvre les clés (les identifiants de ville) et les valeurs (les positions GPS). La table de hachage que nous concevons dans les exercices suivants associera chaque identifiant de ville à une position.
- un constructeur permettant d'initialiser le nom de la ville,
- et une méthode String toString() renvoyant le nom de la ville.
- un constructeur permettant d'initialiser ces champs,
- et une méthode toString() renvoyant la chaîne de caractères "lat, long", dans laquelle lat correspond à la latitude et long à la longitude.
Car l'opérateur == effectue une comparaison par référence, c'est-à-dire qu'il compare la référence evry1 et evry2. Ces deux variables référençant deux objets différents, le résultat est faux. La question suivante explique en détail le problème.
Dans notre exercice, nous sommes intéressés par comparer le contenu des instances de CityId de façon à identifier que evry1 et evry2 sont bien deux identifiants pour la même ville. Cette comparaison des contenus s'appelle la comparaison par valeur, qui est à mettre en opposition à la comparaison par référence effectuée par l'opérateur ==. En effet, la comparaison par référence se cantonne à comparer les références de façon, à savoir si elles référencent bien le même objet.
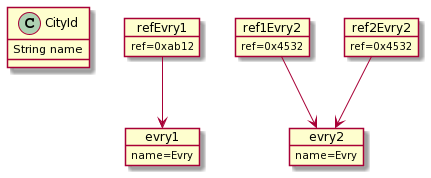
La figure illustre la différence entre une comparaison par référence et une comparaison par valeur. L'état présenté résulte de l'exécution du code suivant :
Les référence refEvry1 et ref1Evry2 sont différentes lorsqu'on effectue une comparaison par référence avec == puisque ces variables référencent deux objets différents (0xab12 est différent de 0x4532). En revanche, ref1Evry2 et ref2Evry2 sont bien égales lorsqu'on effectue une comparaison par référence avec == puisque ces deux variables référencent bien le même objet (les deux variables référencent l'objet 0x4532).
Une comparaison par valeur indique si deux objets sont similaires dans un sens défini par le développeur. Dans notre cas, deux instances de CityId sont égales si elles possèdent des champs noms constitués des mêmes lettres. C'est le cas des objets référencés par refEvry1 et ref1Evry2 dans la figure.
Comme on pourrait imaginer ajouter d'autres champs non significatifs pour la comparaison, Java ne peut pas deviner comment comparer les valeurs de deux objets. Pour cette raison Java ne fournit pas d'opérateur spécifique permettant d'effectuer une comparaison par valeur. À la place, la classe Object définit une méthode de comparaison par valeur boolean equals(Object o) générique qui peut donc être spécialisée par n'importe quelle classe puisque toutes les classes héritent de Object.
De façon à effectuer une comparaison par valeur, ajoutez une méthode public boolean equals(Object o) à la classe CityId. Cette méthode doit déjà vérifier que o est bien du type CityId en utilisant l'opérateur Java instanceof. Ensuite, si c'est le cas, cette méthode doit trans-typer vers le bas (downcast) o en CityId et renvoyer vrai si les champs name de this et o sont égaux.
Comme expliqué précédemment, il faut être capable de calculer la clé de hachage d'une clé. Nous enrichissons donc la classe CityId de façon à calculer son code de hachage. La classe Object définit une méthode d'instance générique public int hashCode() dédiée au calcul de code de hachage. Nous vous proposons donc de spécialiser cette méthode dans CityId.
Comme code de hachage, nous pourrions renvoyer n'importe quelle valeur, pourvu que les codes de hachage de deux objets égaux dans le sens comparaison par valeur (on vous rappelle que dans notre cas, deux clés sont égales si elles ont les mêmes noms de villes) soient égaux. En effet, cet invariant est fondamental : si deux clés égales k1 et k2 avaient des codes de hachage h1 et h2 différents, la recherche de k2 dans l'entrée h2 du tableau de hachage ne permettrait pas de retrouver la clé k1 se trouvant à l'entrée h1.
De façon à assurer l'unicité du code de hachage de deux clés différentes, et de façon à assurer que les collisions de code de hachage sont rares, nous vous proposons de réutiliser la méthode d'instance hashCode() de la classe String (cette méthode effectue des additions et des opérations binaires à partir des numéros des caractères constituant la chaîne de caractères). Notre méthode d'instance CityId.hashCode() doit donc simplement renvoyer le résultat de l'appel à hashCode() sur le champ name d'une instance de CityId.
Dans votre méthode main, vérifiez que evry1 et evry2 ont bien le même code de hachage.
La liste doublement chaînée circulaire (∼1h – difficile – obligatoire)
Avant de se lancer dans la mise en œuvre d'une table de hachage complète, nous commençons par gérer la liste permettant de stocker les clés qui entrent en collision dans la table de hachage. Cette liste est elle-même une table d'associations puisqu'elle associe aussi des clés et des valeurs.
Nous vous proposons de construire cette liste à partir d'une liste doublement chaînée circulaire. Dans cet exercice, nous concevons la liste doublement chaînée circulaire. Nous nous préoccupons de la transformer en table d'associations dans l'exercice suivant, et nous finissons par construire la table de hachage complète dans les deux exercices qui suivent.
Une liste doublement chaînée circulaire est une liste chaînée circulaire, c'est-à-dire que le dernier nœud référence le premier nœud. C'est aussi une liste doublement chaînée, c'est-à-dire qu'un nœud possède une référence avant (next) comme dans une liste chaînée classique, mais aussi une référence arrière (prev) vers le nœud qui le précède dans la liste. Comparée à la liste simplement chaînée non circulaire que vous avez vue en CI2, la liste doublement chaînée circulaire rend le code de suppression d'un nœud beaucoup plus simple.
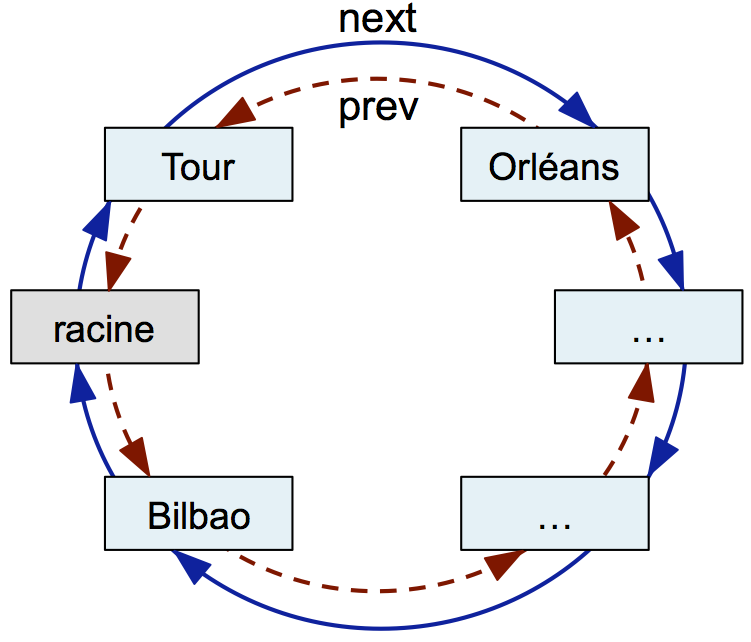
La figure ci-dessus présente une liste doublement chaînée circulaire de villes. Le premier nœud (en gris) s'appelle le nœud racine. Il représente un point d'entrée dans la liste. Les flèches pleines en bleu représentent les références vers l'avant (next) et les flèches rouges en pointillé représentent les références vers l'arrière (prev). Si on suit les références vers l'avant, on voit que la racine référence la première ville, ici Tours. Ensuite, une chaîne de ville permet d'atteindre la dernière ville, ici Bilbao. Enfin, la dernière ville référence la racine pour rendre la liste circulaire. De façon similaire, on peut parcourir la liste dans le sens inverse en suivant le chaînage prev.
Ajoutez une classe nommée ListMap au package tsp.hashmap. Cette classe associe des clés à des valeurs et doit donc être paramétrée par deux types génériques : le type K donne le type de la clé alors que le type V donne le type de la valeur. La classe ListMap représente un des nœuds de la liste doublement chaînée circulaire. Elle doit donc posséder les champs privés next, prev, key et value.
- ListMap<K, V> next référence le nœud suivant de la liste,
- ListMap<K, V> prev référence le nœud précédent de la liste,
- K key référence la clé associée au nœud,
- V value référence la valeur associée au nœud,
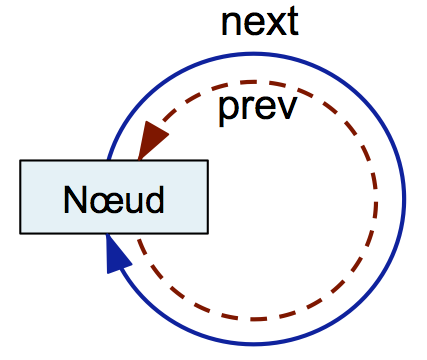
Ajoutez un constructeur à ListMap permettant d'initialiser un nœud de la liste chaînée. Ce constructeur doit prendre en argument une clé et une valeur et les affecter aux champs adéquats. Ce constructeur doit aussi initialiser les références next et prev de façon à ce que le nœud alloué soit une liste doublement chaînée circulaire constituée d'un unique nœud. La figure ci-dessous illustre cet état initial.
Dans la méthode main, allouez une instance de ListMap paramétrée de façon à associer des CityId à des Location. Initialisez cette instance avec le CityId et le Location que vous avez déjà créés à l'exercice précédent. Comme la classe ListMap n'est pas dans le même package que la classe Main, on vous rappelle que pour importer une classe X d'un package a.b.c, il faut mettre import a.b.c.X; dans l'entête du fichier Java.
Finalement, affichez sur le terminal cette instance de ListMap, et vérifiez que vous obtenez bien un affichage similaire à celui-ci :
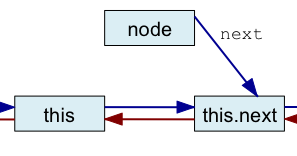
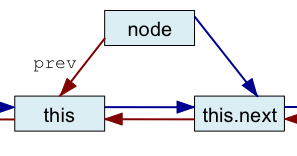
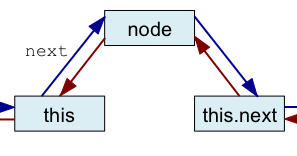
Nous écrivons maintenant une méthode permettant d'insérer un nœud dans une liste circulaire doublement chaînée. Pour le moment, nous ne nous soucions pas d'assurer l'unicité des clés, ce sera le sujet d'une prochaine question. Ajoutez une méthode d'instance append prenant en paramètre une clé et une valeur. Cette méthode insère un nœud associant la clé à la valeur passée en paramètre après le receveur de l'appel (this).
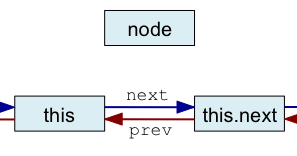
La série de figures ci-dessous illustre l'algorithme que vous devez mettre en œuvre où node est le nouveau nœud à insérer dans la chaîne.
|
|
|

|
|
| Avant insertion | Première étape | Seconde étape | Troisième étape | Quatrième étape |
| node.next = this.next | node.prev = this | this.next.prev = node | this.next = node |
Comme présenté dans la figure au début de l'exercice, une liste doublement chaînée circulaire possède une racine. Ce nœud racine est un faux nœud, c'est-à-dire qu'il ne stocke pas de clé ou de valeur. Il ne sert que de point d'entrée dans la liste, même quand la liste est vide. Il s'agit techniquement d'un nœud référençant la clé null et la valeur null.
De façon à préparer les tests suivants, commencez par supprimer tout le code qui se trouve dans la méthode main. À la place, créez un nœud racine nommé root et utilisez append pour ajouter au moins 3 villes avec des coordonnées quelconques. Si, lorsque vous lancez votre programme, Eclipse vous signale l'erreur NullPointerException, cela signifie que le code de append est incorrect et il faut que vous recommenciez la question f.
Ajoutez une méthode void display() à la classe ListMap permettant d'afficher les couples clé/valeur de chacun des nœuds de la liste. Cette méthode considère que le receveur de l'appel est une racine et n'affiche donc pas son contenu. En revanche, elle affiche le résultat de l'appel à toString() sur chacun des nœuds de la liste. Vérifiez que votre code est correct en appelant display sur la liste root que vous avez construite à la question précédente. Vous devriez obtenir un affichage similaire à celui-ci :
Pour vous guider, vous pouvez parcourir la liste en écrivant une boucle qui commence avec le premier nœud après la racine, qui suit les références next, et qui s'arrête quand la racine est atteinte.
La table d'associations basée sur les listes (∼ 30mn – moyen – obligatoire)
Dans cet exercice, nous terminons notre mise en œuvre de la liste doublement chaînée circulaire de façon à la transformer en table d'associations.
Ajoutez à la classe ListMap une méthode ListMap<K, V> lookupNode(K key) permettant de retrouver un nœud associé à la clé key dans la liste. Cette méthode doit parcourir la liste, un peu comme vous l'aviez fait dans la méthode display. Si pendant le parcours, vous trouvez un nœud avec une clé égale (dans le sens comparaison par valeur, c'est-à-dire en utilisant equals) au paramètre de la méthode, il faut renvoyer ce nœud, sinon, il faut renvoyer la valeur null.
Dans la méthode main, vérifiez que votre code est correct en essayant (i) de trouver le nœud associé à l'une de vos villes dans la liste root, et (ii) de trouver une ville qui n'y est pas.
Ajoutez une méthode V get(K key) renvoyant la valeur associée à la clé key si elle existe et null sinon. Cette méthode peut bien sûr appeler lookupNode pour retrouver le nœud associé à key.
Ajoutez une méthode boolean remove(K key) permettant de supprimer une association et renvoyant vrai si et seulement si l'association existait avant l'appel. Cette méthode peut bien sûr appeler lookupNode pour retrouver le nœud associé à key. Dans la méthode main, supprimez l'une de vos villes et appelez display() pour vérifier que votre liste est correcte.
Pour supprimer un nœud N d'une liste doublement chaînée circulaire, il suffit que le prédécesseur de N joigne directement le suivant de N et réciproquement. Techniquement, il faut que le suivant du prédécesseur de N référence le suivant de N, et que le prédécesseur du suivant de N référence le prédécesseur de N.
Afin de tester votre code, supprimez tout le code qui se trouve dans la méthode main. À la place, copiez-collez le code suivant :
L'exécution de ce test devrait vous générer un affichage similaire à celui-ci :
L'interface d'une table d'associations (∼ 20mn – moyen – obligatoire)
Avant de mettre en œuvre les tables de hachages, nous abstrayons la notion de table d'associations sous la forme d'une interface.
Dans le package tsp.hashmap, ajoutez une interface nommée Map paramétrée par le type K d'une clé et le type V d'une valeur. Ensuite, ajoutez les méthodes suivantes à l'interface :
- boolean put(K key, V value) : crée une association et renvoie vrai si la clé n'avait aucune association auparavant,
- V get(K key) : renvoie la valeur associée à key si elle existe et null sinon,
- boolean remove(K key) : supprime l'association de key et renvoie vrai si elle existait,
- void display() : affiche toutes les associations de la table d'associations sur le terminal.
Enfin, modifiez la déclaration de ListMap afin qu'elle mette en œuvre Map. Si le code de ListMap est correct, vous ne devriez rien avoir à faire d'autre puisque les méthodes de l'interface Map sont déjà mises en œuvre dans ListMap.
Maintenant que nous avons une interface générique de table d'associations, nous pouvons nous en servir dans la méthode main. Au début du main, remplacez la déclaration :
par
de façon à s'assurer que le code de main n'utilise que l'interface d'une liste d'associations et ne dépend pas des détails de mise en œuvre. Vérifiez que votre code s'exécute toujours correctement.
La table de hachage (∼ 30mn – moyen – entraînement)
Maintenant que nous avons conçu toutes les classes et interfaces de base, nous pouvons enfin mettre en œuvre les tables de hachage. Techniquement, notre table de hachage est simplement un tableau de ListMap : les ListMap permettent de gérer les clés qui entrent en collision.
- put renvoie toujours faux,
- get renvoie toujours null,
- remove renvoie toujours faux,
- display ne fait rien.
- Calculer le code de hachage H de key en appelant hashCode().
- Effectuer un modulo de H avec la taille du tableau de hachage (table.length). Le résultat r de ce modulo devrait donner l'indice du TableMap dans le tableau table dans lequel key doit se trouver. Toutefois, en Java, le modulo d'un nombre négatif reste négatif et ne peut pas directement être utilisé comme indice dans table. Si ce modulo est négatif, il faut que vous y ajoutiez table.length pour le rendre positif.
- Renvoyer le ListMap se trouvant à l'indice r de table.
Si nous revenons à HashMap, le pire des cas se produit si tous les hashs entrent en collision. Dans ce cas, une seule ListMap contient toutes les données et la complexité de toutes les opérations est linéaire en le nombre d'éléments dans le HashMap.
Pour approfondir (entraînement)
Si vous obtenez une implémentation différente de la nôtre, c'est tout à fait normal !
Attention, il faut réinsérer tous les éléments !
On pourra ajouter un nouveau constructeur prenant en argument la capacité du tableau interne, c'est-à-dire sa taille. De plus, on pourra utiliser un HashMap temporaire et modifier le tableau interne au dernier moment.
Il peut être utile de rajouter dans Map une méthode addAllTo(HashMap<K, V> map) qui ajoute tous les éléments du Map actuel au HashMap. Cette solution temporaire nous permet de ne pas briser l'encapsulation. Nous verrons dans un prochain cours que nous pourrions utiliser des itérateurs à la place.
Faites en sorte que le tableau se redimensionne automatiquement quand il atteint une certaine taille.
On pourra utiliser un champ size qui s'augmente à chaque ajout nouveau au HashMap et diminue à chaque retrait effectif.
La preuve formelle ressemble à celle du tableau extensible des TPs précédents.
- boolean add(E element) : Ajoute un élément dans le set. On renvoie vrai si cet élément n'était pas déjà dans le set.
- boolean remove(E element) : Supprime un élément dans le set. On renvoie vrai si cet élément était bien dans le set.
- boolean contains(E element) : Renvoie vrai si cet élément est dans le set.
File et pile ! (entraînement)
Créer une classe générique Queue. Cette classe fonctionnera de la même manière que la liste doublement chaînée. Elle aura deux constructeurs : un sans argument (ce qui créera une liste vide) et un autre avec un seul argument, ce qui crée une liste avec un seul argument. Comme pour la liste double chainée, nous retrouverons les attributs next, prev, et value (la clef n'est plus utile). Pour savoir si une liste est vide ou non, nous utiliserons un argument supplémentaire isEmpty.
Pour l'instant, isEmpty vaut true uniquement pour le constructeur sans argument.
Si la file était vide, on ne remplacera que la valeur actuelle (et on mettra à jour isEmpty).
- Si la file est vide, on retourne null.
- Si la file ne contient qu'un seul nœud, on rend la file vide est on retourne la valeur actuelle.
- Sinon, on retourne la valeur actuelle. Cependant, avant cela, on copie la valeur next sur le nœud actuel et on supprime le nœud suivant.
Un moteur de recherche de documents (entraînement)
Cet exercice vous laisse une certaine liberté sur l'implémentation, il est donc normal de ne pas retrouver exactement le même code que nous.
Vous aurez besoin de Map et de Set. Vous pouvez soit réutiliser votre implémentation, soit utiliser celle directement donnée par Java, aussi appelées HashSet et HashMap (faites attention aux imports).
Un terme est simplement un mot en minuscule. Écrivez une fonction preprocess qui retourne un tableau de String correspondant aux mots en minuscule dans le document (attention aux fins de lignes).
Par exemple, "Je suis un lion.\nJe mange de l'herbe." devient {"je", "suis", "un", "lion.", "je", "mange", "de", "l'herbe."}.
La documentation de String va vous aider. En particulier, les méthodes String toLowerCase() et String[] split(String regex).
Imaginons que nous voulions maintenant rajouter la possibilité de créer un document à partir d'un fichier ou à partir d'une URL. Dans les deux cas, nous désirons donner un nom du fichier ou l'URL sous forme d'une String. Mais il y a un problème : le constructeur prenant en entrée une String est déjà pris. On pourrait imaginer d'autres solutions:
- Rajouter des paramètres au constructeur pour dire si l'on passe le contenu, un nom de fichier ou une URL. Cependant, cette solution est très verbeuse et n'est pas très flexible (que faire si je veux rajouter une nouvelle manière de créer un document ?).
- On pourrait étendre la classe document avec des classes filles DocumentURL et DocumentFile. Cependant, cette solution oblige à créer des classes uniquement dans le but de remplacer le constructeur, ce qui n'est pas forcément optimal.
- On peut utiliser une fabrique (factory en anglais). Une fabrique est une méthode statique spécialisée dans la création d'objets. C'est un patron de conception classique qui a beaucoup d'avantages (c.f. le cours CSC 4102 – Introduction au génie logiciel pour applications orientées objet). Vous avez déjà rencontré des fabriques sans le savoir à travers la méthode Integer.valueOf(String s) qui permet de "fabriquer un entier" à partir d'une chaîne de caractères.
Nous donnons ici deux fonctions permettant de lire un document à partir d'un fichier ou d'une URL.
Écrivez deux fabriques statiques fromFile et fromURL à partir des deux fonctions données au-dessus.
En pratique:
- Créer un champ HashMap<String, ArrayList<Document>> inverseIndex
- Implémentez une méthode void add(Document document)
Écrivez une fonction pour obtenir l'IDF d'un mot (double getIDF(String word)), puis une fonction pour obtenir le TFIDF d'un mot et d'un document (double getTFIDF(String word, Document document)). Le TFIDF est simplement le produit de la TF et de l'IDF:
Par exemple, "the peter pan and peter" deviendra "peter pan" car "peter" apparait deux fois et "the" et "and" sont trop populaires.
Écrivez cette méthode de prétraitement String[] getWordsQuery(Document query).
- Récupérer la liste des documents potentiels (c'est-à-dire contenants au moins un mot de la requête pré-traitée)
- Calculer un score pour chacun de ces documents. Pour faire simple, nous définissons le score comme étant la somme des TFIDF des mots de la requête (pré-traitée).
- Prendre le meilleur document.
Quel livre correspond à la requête ""pirate island" ?
