Sensibilisation à la programmation concurrente (multitâche) à travers C++ (Cours Intégré)
Table des matières
- 1. Préparation de la dimension "Intégré" de ce cours intégré
- 2. Introduction
- 3. Multitâche pour accélérer les performances
- 3.1. Code 01 : Un exemple d'application permettant de comprendre une motivation du multithreading
- 3.2. Outil : volatile
- 3.3. Outil : Threads
- 3.4. Code 02 : Exemple de parallélisation avec des threads (et outil Diagramme de séquence)
- 3.5. Outil : Diagramme de séquence
- 3.6. Outil : Mutex (pour gérer les exclusions mutuelles)
- 3.7. Code 03 : Utilisation de mutex pour définir le pattern de synchronisation "Section critique" et éviter les Data Race
- 3.8. Outil : variable
Atomic - 3.9. Code 04 : Opération
Atomic - 3.10. Bonne pratique : Eviter les variables mutables pour n'avoir que des variables non-mutables et patron d'architecture MapReduce
- 3.11. Code 05 : Exemple de mise en oeuvre de MapReduce
- 3.12. Outil : Tâche (future ou
std::async()) - 3.13. Code 06 : Exemple d'utilisation de tasks
- 4. Spécificités C++
- 4.1. Outil : Lock
- 4.2. Code 07 : S'appuyer sur la RAII pour déverrouiller automatiquement (notion spécifique C++)
- 4.3. Bonne pratique : Utilisation de variables static dans un Block scope
- 4.4. Outil : thread_local (stockage spécifique à chaque thread)
- 4.5. Code 08 : Exemple d'utilisation de static et de thread_local
- 4.6. Code 09 : atomic ne peut pas être utilisé sur un std::vector
- 5. Multitâche pour gérer de multiples activités en parallèle
- 6. Variables "Condition" ("Moniteur") pour de nouveaux patrons (patterns) de synchronisation
- 6.1. Outil : Variable "Condition" ("Moniteur")
- 6.2. Code 10 : Pattern de synchronisation Cohorte à base de moniteur
- 6.3. Code 11 : Pattern de synchronisation Loquet (Latch) avec moniteur (N threads contrôlent 1 thread)
- 6.4. Code 12 : Pattern de synchronisation Loquet (Latch) avec moniteur (1 thread contrôle N threads)
- 6.5. Outil :
std::latch - 6.6. Code 13 : Pattern de synchronisation Loquet (Latch) avec
std::latch(N threads contrôlent 1 thread) - 6.7. Code 14 : Pattern de synchronisation Loquet (Latch) avec
std::latch(1 thread contrôle N threads) - 6.8. Outil :
std::barrier - 6.9. Code 15 : Pattern de synchronisation Barrière (Latch) avec
std::barrier - 6.10. Pattern de synchronisation Producteur / Consommateur
- 6.11. Code 16 : Pattern de synchronisation Producteur / Consommateur avec queue illimitée
- 6.12. Code 17 : Pattern de synchronisation Producteur / Consommateur avec production régulée
- 7. Variables semaphore pour une autre manière de synchroniser
- 7.1. Outil : Sémaphores
- 7.2. Code 18 : Pattern de synchronisation Cohorte à base de sémaphore
- 7.3. Pattern de synchronisation Rendez-vous
- 7.4. Pattern de synchronisation Lecteurs-Rédacteurs
- 7.5. Code 19 : Pattern de synchronisation Lecteurs-Rédacteurs avec sémaphore
- 7.6. Outil : Verrou pour lecteurs-rédacteur (
std::shared_lock) - 7.7. Code 20 : Pattern de synchronisation Lecteurs-Rédacteurs avec verrou lecteurs-rédacteur
- 8. Autres notions importantes
- 8.1. Bonne pratique : Gestion de la mémoire (allocation/désallocation)
- 8.2. Code 21 : Serveur TCP avec
shared_ptr - 8.3. Code 22 : Serveur TCP avec
unique_ptr - 8.4. Code 23 : Serveur TCP sans pointeurs
- 8.5. Outil : Thread-safe initialisation
- 8.6. Outil : Algorithmes parallèles de la STL (Standard Template Library, C++17)
- 8.7. Code 24 : Algorithmes parallèles de la STL et execution policy
- 8.8. Code 25 : Algorithmes parallèles de la STL et risque de Data Race
- 8.9. Outil : Coroutines (C++ 20)
- 8.10. Code 26 : Coroutine
- 8.11. Fibres
- 8.12. Debug, Profiling
- 8.13. What should come in C++ 23
- 9. Threads versus Autres modèles de programmation
- 10. Conclusion
- 11. Bibliographie
- 12. Remarques de relecture sur ce cours
1. Préparation de la dimension "Intégré" de ce cours intégré
Ce Cours Intégré a été testé sur Windows et Linux (il reste à le tester sur MacOS). Il nécessite des travaux préparatoires décrits dans cette section :
- Installation de l'IDE
- Dans le cas où vous avez déjà installé VisualStudio (Entreprise ou Community) avec C++ :
- Mettre à jour VisualStudio si vous êtes à une version strictement inférieure à 16.11.3
- Mettre à jour SonarLint (dans VS, menu Extensions > Gérer les mises à jour > Mise à jour, mettre à jour SonarLint s'il est mentionné) NB : Si vous n'avez pas installé SonarLint, suivez les instructions en section 2.3 de https://www-inf.telecom-sudparis.eu/COURS/CSC4526/new_site/Supports/Documents/InstallationIDE/installationIDE.html#orgbe7fc38
- Dans le cas où vous n'avez jamais installé Visual Studio sur votre machine (NB : ne vous contentez pas de Visual Studio Code !), faire les sections 2 et 3 de https://www-inf.telecom-sudparis.eu/COURS/CSC4526/new_site/Supports/Documents/ExoIntroduction/exoIntroduction.html
- Dans le cas où vous avez déjà installé VisualStudio (Entreprise ou Community) avec C++ :
- Une fois l'IDE installé, décompressez l'archive ProgrammationConcurrente.zip dans le répertoire de votre choix.
- Enfin, exploitez le canevas de projet obtenu selon la procédure
cmakede ce document.
2. Introduction
2.1. Génèse de ce cours
Message envoyé sur Discord par un étudiant JIN durant l'année 2020-2021 :
Depuis quelques temps, j'observe que la majorité des tests techniques que nous devons passer dans le jeu vidéo traitent de multithreading. Or, au cours de notre scolarité, nous n'avons jamais abordé cela, ce qui fait que nous sommes systématiquement pénalisés. Et ce que ce soit à l'ENSIIE, ou à TSP (apparemment il s'agit d'une option de seconde année à TSP mais abordée de manière trop fragile, donc tout le monde ne l'a pas vu ou mal vu). Je pense que pour le jeu-vidéo, le multithreading est de plus en plus primordial à manipuler, aussi je viens vous suggérer d'aborder la question au cours du semestre de JIN. Je ne sais pas vraiment à quel moment cela peut se faire (peut-être au tout début de l'année sur le projet Unity avec monsieur Bouyer ?) mais il me semble important de parler de ce point, afin d'arriver moins décontenancés face aux tests techniques. Qu'en pensez-vous ?
Réponse à ce message = le présent Cours Intégré de 3h30 qui a pour objectif de vous présenter les notions essentielles, sans pouvoir tout détailler.
2.2. Objectifs de ce cours
- Présenter :
- Les outils liés au multitâche (plus exactement à la concurrence)
- Threads et tâches (On met donc de côté la programmation multi-processus et la programmation distribuée (même si on retrouve les mêmes notions)
- Outils de synchronisation
- Les patrons de synhronisation (synchronization patterns) classiques
- Les bonnes pratiques
- Les outils liés au multitâche (plus exactement à la concurrence)
- Illustrer cela avec des exemples de code C++ (en indiquant quand le code présenté est une spécificité C++).
- Vous donner l'envie d'imaginer un concept de jeu qui illustrerait
tous ces mécanismes
- Wooclap à la fin de la séance sur ce sujet !
- Projet de 2ème année TSP cette année ? PFE JIN l'an prochain ?
2.3. Quelle version de C++ ?
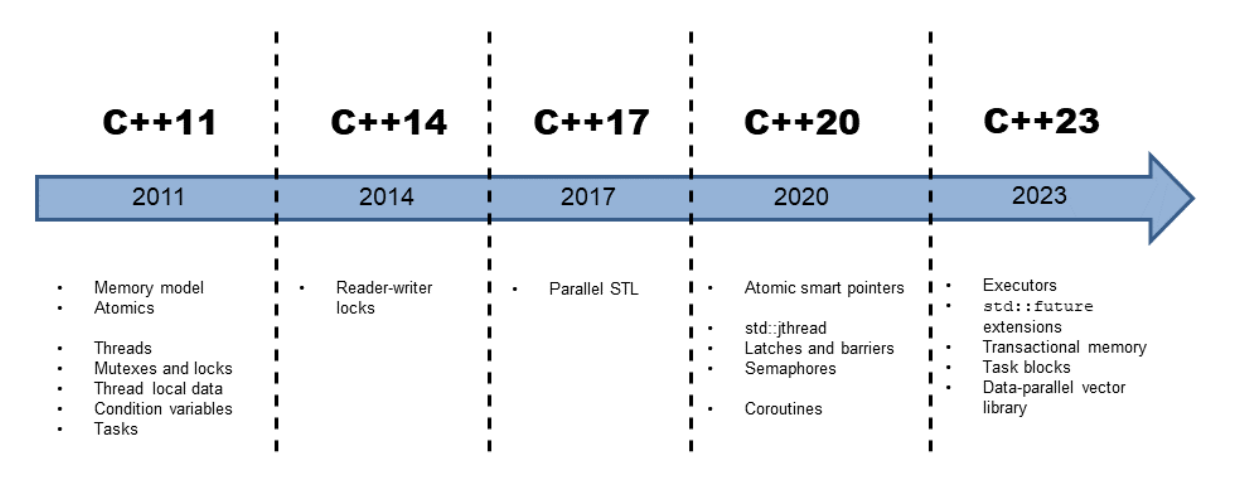
La plupart des notions présentées ici sont anciennes. Par exemple, les sémaphores ont été inventés par Dijkstra dans les années 1960, alors qu'ils n'ont été intégrés qu'à C++ 20. En général, des notions apparaissant après C++ 11 peuvent être implémentées :
- en s'appuyant sur des fonctionnalités C++ 11.
- OK pour portabilité ; KO pour lisibilité et performances.
- Exemple : Un sémaphore (C++ 20) peut être implémenté avec un
mutexet unestd::condition_variable(C++ 11).
- en invoquant directement des appels système.
- KO pour portabilité ; OK pour performances ; ? pour lisibilité.
- Exemple : Un sémaphore (C++ 20) peut être implémenté en utilisant
les sémaphores de la bibliothèque pthread (ex. :
sem_init) ou ceux de Windows (ex. :CreateSemaphore).
Pour compiler les exemples, il est nécessaire de disposer d'un compilateur à jour :
- Au moins Visual Studio 16.11.3 (septembre 2021)
- Au moins gcc 11.1 (avril 2021). Le support de C++ 20 a l'air assez complet (cf. cette page).
- Pour Ubuntu, cet article explique comment faire cohabiter le gcc standard et le gcc plus avancé.
- Concernant clang
- Clang MacOS est en retard quant à l'adoption de C++ 20 (comparer les colonnes "Clang" et "Apple clang" en https://en.cppreference.com/w/cpp/compiler_support/20). Notez que les compilateurs Clang et Apple clang n'ont pas les mêmes numéros de version.
- Sur Ubuntu/Windows, théoriquement, au moins clang 14.0.0. Pour ce cours, nous n'avons testé que
la compilation des sources de ce cours avec clang 17.0.6 que nous avons installé sous Ubuntu
de la manière suivante :
- Suivre les instructions en https://ubuntuhandbook.org/index.php/2023/09/how-to-install-clang-17-or-16-in-ubuntu-22-04-20-04/
- Pour utiliser ensuite clang à la place de gcc, ouvrir un
terminal et y taper les intructions suivantes (NB : c'est
ensuite dans ce terminal qu'on fera
cmakeetmake) :
# cf. https://ubuntuclub.org/how-to-use-clang-instead-of-gcc-in-ubuntu/ export CC=/usr/bin/clang-17 export CPP=/usr/bin/clang-cpp-17 export CXX=/usr/bin/clang++-17 export LD=/usr/bin/ld.lld-17 #Description of environment variables: # CC : C compilerclang # CPP : C precompiled processorclang-cpp # CXX : C++ compilerclang++ # LD : Linkerld.lld
3. Multitâche pour accélérer les performances
Tout au long de ce chapitre, nous allons comparer différents codes destinés à accélérer les performances, ce qui permettra de comprendre certains fonctionnements internes de l'ordinateur. Pour noter et commenter les résultats des expériences menées, nous vous invitons à télécharger cette feuille de calcul et à y consigner le résultat de chacune des expériences.
3.1. Code 01 : Un exemple d'application permettant de comprendre une motivation du multithreading
6: constexpr int nb_count = 100000000; 7: 8: int main() { 9: auto counter = nb_count; 10: 11: const auto start = high_resolution_clock::now(); 12: const auto start_cpu = get_cpu_time(); 13: auto i = nb_count; 14: while (i > 0) { 15: --counter; 16: --i; 17: } 18: const auto end_cpu = get_cpu_time();
3.1.1. Expériences
- Générez votre code en mode Debug, puis exécutez-le sans débogage (Ctrl + F5).
- Quelles valeurs de
counteret elapsed time (temps d'exécution) obtenez-vous ?
- Quelles valeurs de
- Débrachez votre machine et réexécutez votre code sans débogage (Ctrl + F5).
- Quelles valeurs de
counteret elapsed time (temps d'exécution) obtenez-vous ?
- Quelles valeurs de
- Rebranchez votre machine (et gardez-la branchée pour le reste du TP).
- Pour le fun, dans un terminal :
- Allez dans le répertoire contenant
Source_01.cppetSource_01.py(la version Python de ce code). Par exemple,cd ProgrammationConcurrente/01_CounterMonothread - Tapez la commande :
python3 Source_01.py - Quelles valeurs de
counteret elapsed time obtenez-vous ? - Calculez le rapport entre l' elapsed time de votre programme Python et l' elapsed time de votre programme C++. Commentez.
- Allez dans le répertoire contenant
- Générez maintenant votre code en mode Release
- Sous Visual Studio
- Dans la barre de menu, cliquez sur la flèche à droite de
x64-Debuget sélectionnezGérer les configurations: Un ongletCMakeSettings.jsons'ouvre. - Dans cet onglet, dans
Configurations, cliquer sur le bouton "+" et sélectionnezx64-Release - Fermez l'onglet
CMakeSettings.json - Dans la barre de menu, sélectionnez
x64-Releaseà la place dex64-Debug: Votre projet est regénéré en mode Release
- Dans la barre de menu, cliquez sur la flèche à droite de
- Sous CLion
- Menu
File>Setting: Une fenêtre de "Settings" s'ouvre. - Sélectionnez
Build, Execution, Deployment>CMake: Le sous-menuCMakes'ouvre. - Dans la colonne de gauche des profils, là où il n'y a que la
mention
Debug, cliquez sur le bouton "+" : Un itemReleaseest créé. - Patientez un peu le temps que le projet se regénère.
- Dans la liste déroulante avec
01_CounterMonothread | Debug, vous pouvez maintenant sélectionnerRelease, puis sélectionner01_CounterMonothread | Release
- Menu
- Sous XCode
- TODO A compléter
- Sous Visual Studio
- Exécutez Code 01 en mode Release et sans débogage (Ctrl + F5).
- Quelles valeurs de
counteret elapsed time obtenez-vous ?
- Quelles valeurs de
- Cet elapsed time est dû au fait que le compilateur fait des
optimisations: Il constate qu'il n'a pas besoin de faire toute la
boucle pour trouver son résultat, i.e. que
countervaut 0 à la fin de la boucle. Il remplace donc la boucle par l'écriture de 0 danscounter. - Ajoutez le mot-clé
volatiledevantauto counter = nb_count;Cela indique au compilateur de faire aucune optimisation liée àcounter.- Remarquez que SonarLint vous dit "Check if the usage of the type 'volatile int' is really appropriate here (for inter-thread synchronization, atomic types are more suited)." Nous ignorons ce message pour l'instant.
- Quelles valeurs de
counteret elapsed time obtenez-vous ?
- Voyons si ce résultat fait sens :
- Récupérez la fréquence de votre processeur (Sous Windows, affichez les paramètres Windows et cherchez "A propos": Windows affiche la fréquence du processeur).
- Cette fréquence indique le nombre d'instructions qu'exécute votre ordinateur chaque seconde. Déduisez-en le temps nécessaire pour que votre processeur exécute une instruction.
- Le code de votre boucle est grosso-modo compilé en assembleur de
la manière suivante (Si vous voulez voir le code assembleur, sous
Visual Studio, mettez un point d'arrêt au niveau de
--counter;, lancez en mode debug, et affichez le code assembleur en appuyant sur Ctrl+Alt+D ; Sous CLion, même procédure, mais touches Alt+Shift+F7) :
Etiquette_début_boucle: Si registre i <= 0 saute à Etiquette_fin_boucle
Charge counter dans un registre
Décrémente de 1 ce registre
Stocke ce registre dans counter
Décrémente i
Saute à Etiquette_début_boucle
Etiquette_fin_boucle: etc.
- Le traitement de chaque "tour" de boucle nécessite donc 6 instructions assembleur. Multipliez donc le temps de traitement d'une instruction par 6 et par 100.000.000 (nombre de "tours" de boucle) : Vous devriez obtenir un temps proche du temps d'exécution observé (en fait, le temps d'exécution observé est légèrement inférieur grâce au pipeline du processeur).
- Dans la suite, nous travaillerons systématiquement en mode Debug
(donc,
x64-Debuget nonx64-Release) pour éviter que le compilateur fasse des optimisations sans nous le dire. Cela nous évitera de systématiquement ajouter la mentionvolatileaux variables que nous partagerons entre threads. - Si on souhaite réduire le temps d'exécution, on pourrait chercher à
réduire le temps d'exécution de chaque instruction, i.e. augmenter
la fréquence du processeur. C'est ce qu'ont fait les constructeurs
pendant des années :
- Apple 2 (1977) : processeur 8 bits à 2,8 MHz
- Premier IBM PC (1981) : processeur (registres 16 bits, bus 8 bits) à 4,77 MHz
- etc.
- Toutefois, des fréquences au delà de 2,9 GHz entrainent des problèmes de refroidissement du processeur. Ainsi, le record d'overclocking est actuellement de 9,04392 Ghz grâce à un refroidissement à l'hélium liquide permettant d'atteindre -250°C (cf. cet article et cet Hall of Fame).
- Les constructeurs ont donc proposé que les processeurs soient constitués de plusieurs coeurs, ce qui permettrait de paralléliser les calculs à faire.
- Et, pour permettre la parallélisation des calculs, les développeurs de systèmes d'exploitation ont introduit la notion de thread, avec des appels systèmes pour la mettre en oeuvre. Ainsi, le développeur peut disposer de plusieurs "main" dans son programme.
- Enfin, les langages de haut niveau ont évolué pour offrir des
abstractions qui
- cachent les appels système,
- facilitent la portabilité entre des systèmes d'exploitation différents,
- Offrent des services de plus haut niveau au dessus des appels système.
3.2. Outil : volatile
Notions essentielles
- Ce mot-clé est disponible dans la plupart des langages de programmation.
- Il permet de dire au compilateur qu'il ne faut pas faire d'optimisation concernant une variable.
- Voir exemple en Code 01.
3.3. Outil : Threads
- Un thread est une entité système beaucoup plus légère (en temps de création et en mémoire) qu'un processus.
- Un thread a sa propre pile dans l'espace mémoire d'un processus (donc, la pile d'un thread est moins grande).
- Opérations sur les threads
- Création
join: Attente de la terminaison d'un thread enfant par son créateur.detach: Coupure du lien entre le thread enfant et son créateur.
- Les threads sont préemptifs, c'est-à-dire que, quand ils s'exécutent, ils peuvent être interrompues à n'importe quel moment par un autre thread. Nous verrons plus loin d'autres modèles de programmation.
- En Java, possibilité de définir des priorités d'exécution pour les
threads. Non disponible dans le standard C++, mais contournement
possible avec
std::thread::native_handle()(Attention : appel pas obligatoirement implémenté).
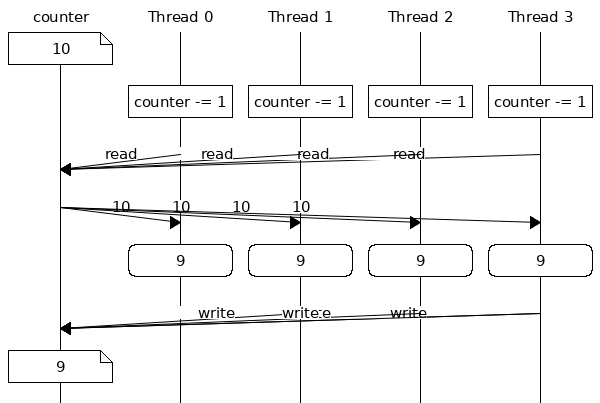
3.4. Code 02 : Exemple de parallélisation avec des threads (et outil Diagramme de séquence)
8: constexpr int nb_count = 100000000; 9: constexpr int nb_threads = 4; 10: 11: void decrement(const int nb_decrement, int& counter) { 12: for (auto i = nb_decrement; i > 0; --i) { 13: --counter; 14: } 15: } 16: 17: int main() { 18: auto counter = nb_count; 19: 20: const auto start = high_resolution_clock::now(); 21: const auto start_cpu = get_cpu_time(); 22: std::vector<std::jthread> threads(nb_threads); 23: for (auto& t : threads) { 24: t = std::jthread(decrement, nb_count / nb_threads, std::ref(counter)); 25: } 26: for (auto& t : threads) { 27: t.join(); 28: }
3.4.1. Expériences
- Nous utilisons
std::threadspour paralléliser notre code.- Vérifiez que vous comprenez bien le fonctionnement de ce programme.
- En particulier, notez l'utilisation de
std::refpour passer une référence à une variable à un thread. On peut aussi passer une variable par copie ou bien par référence constante (std::cref)
- Générez votre code en mode Debug (pour éviter les optimisations), puis exécutez-le sans débogage (Ctrl + F5).
- Quelles valeurs de
counteret elapsed time obtenez-vous ?
- Quelles valeurs de
- Selon vous, pourquoi
counterne vaut pas zéro ?- Voir section Cours sur "Diagramme de séquence" pour bien comprendre.
- Nous observons une data race, i.e. une situation dans laquelle au moins deux threads accèdent simultanément à la même variable et l'un de ces threads cherche à modifier cette variable. Si votre programme a une data race, son comportement est indéfini. Cela signifie que tout peut arriver et donc raisonner à propos de votre programme n'est plus possible.
- Si vous avez le temps, faites cette digression :
- Commentez
t.join(); - Maintenant, le thread
mainn'attend plus que les autres threads aient fini: Son affichage est donc incorrect. De plus, le programme plante, quand les autres threads se terminent. - Pour éviter ce plantage, vous pouvez ajouter
t.detach(), après chaque création de thread enfant. Autre solution: C++ 20 apportestd::jthread. Remplacezthreadparjthread(comme vous le suggérait SonarLint) et vérifiez que votre programme ne plante plus.
- Commentez
3.5. Outil : Diagramme de séquence
Notions essentielles :
- Un "Diagramme de séquence" peut aider à comprendre les data race.
- Un "Diagramme de séquence" va de haut en bas, alors qu'un "Diagramme de temps" va de gauche à droite ;
mscgen(https://www.mcternan.me.uk/mscgen/) est un outil intéressant pour faire rapidement des diagrammes de séquence.
3.6. Outil : Mutex (pour gérer les exclusions mutuelles)
Notions essentielles
- Opérations sur les mutex
lock: Un thread qui exécute cette instruction prend le mutex. Si un autre thread essaie de prendre ensuite le mutex, cet autre thread est bloqué jusqu'à ce que le premier thread relâche le mutex.unlock: Un thread qui exécute cette instruction relâche le mutex et réveille un des threads qui avait faitlocksur ce même mutex.
- On appelle section critique le code entre les instructions
lock()etunlock(). Le système d'exploitation garantit qu'à tout instant, un seul thread exécutera la section critique. - ==> Pattern de synchronisation "section critique"
- Une section critique doit être la plus courte possible en temps
d'exécution. Donc :
- N'y mettre que le code qui a besoin d'être en section critique.
- Jamais de sleep dans une section critique.
- Les mutex peuvent conduire au cauchemard des verrous mortels (deadlocks) ! Autant que possible, veillez à verrouiller les mutex dans le même ordre.
- NB : En Java, il est aussi possible de définir un méthode (ou un
bloc de code) comme
synchronizedpour éviter que'il y ait des exécutions concurrentes. Microsoft en a fait une extension C++ avec l'attribut{synchronize}non standard, donc à éviter.
3.7. Code 03 : Utilisation de mutex pour définir le pattern de synchronisation "Section critique" et éviter les Data Race
12: void decrement(const int nb_decrement, int &counter) { 13: static std::mutex mtx; 14: for (auto i = nb_decrement; i > 0; --i) { 15: mtx.lock(); 16: --counter; 17: mtx.unlock(); 18: } 19: } 20: 21: int main() { 22: auto counter = nb_count; 23: 24: const auto start = high_resolution_clock::now(); 25: const auto start_cpu = get_cpu_time(); 26: std::vector<std::jthread> threads(nb_threads); 27: for (auto &t : threads) { 28: t = std::jthread(decrement, nb_count / nb_threads, std::ref(counter)); 29: } 30: for (auto &t : threads) { 31: t.join(); 32: }
3.7.1. Expériences
std::mutexest la classe qui nous permet de définir des sections critiques.- Vérifiez que vous comprenez bien le fonctionnement de ce programme.
- Générez votre code en mode Debug (pour éviter les optimisations),
puis exécutez-le sans débogage (Ctrl + F5).
- Quelles valeurs de
counteret elapsed time obtenez-vous ?
- Quelles valeurs de
- Que se passe-t-il si vous oubliez
mtx.unlock()? Essayez en mettant cette instruction en commentaire.- Spécificité C++ : A cause d'une exception, votre programme risque
de ne pas exécuter
mtx.unlock(), même si vous avez bien écrit et compilé cette instruction ! Nous verrons plus loin qu'en définissant unLockadossé aumutex, la RAII nous affranchit de ce problème.
- Spécificité C++ : A cause d'une exception, votre programme risque
de ne pas exécuter
3.8. Outil : variable Atomic
Notions essentielles
- Il est tellement classique de devoir se prémunir contre des
écritures simultanées sur une variable que C++ fournit
atomic(depuis C++ 11). Par exemple :
struct Counters { int a; int b; }; // user-defined trivially-copyable type std::atomic<Counters> cnt; // specialization for the user-defined type std::atomic<int> // or atomic_int
- L'implémentation d'
atomics'appuie sur des instructions dédiées du processeur (==> Plus performant qu'unmutex) - Peut-on déclarer un
std::atomic<std::vector<int>>? Non, car :- C++11 §29.5/1 says: "There is a generic class template atomic. The type of the template argument T shall be trivially copyable (3.9)."
- What does trivially copyable mean? §3.9 tells: "Scalar types, trivially copyable class types (Clause 9), arrays of such types, and cv-qualified versions of these types (3.9.3) are collectively called trivially copyable types."
- Ce n'est pas le cas de std::vector (non-trivial copy constructors, non-trivial move constructors, non-trivial copy assignment operators, non-trivial move assignment operators).
- Voir Code 09 qui ne compile pas avec
std::atomic<std::vector<int>>.
- NB : Java propose aussi cette notion.
3.9. Code 04 : Opération Atomic
12: void decrement(const int nb_decrement, std::atomic_int &counter) { 13: for (auto i = nb_decrement; i > 0; --i) { 14: --counter; 15: } 16: } 17: 18: int main() { 19: std::atomic_int counter = nb_count; 20: 21: const auto start = high_resolution_clock::now(); 22: const auto start_cpu = get_cpu_time(); 23: std::vector<std::jthread> threads(nb_threads); 24: for (auto &t : threads) { 25: t = std::jthread(decrement, nb_count / nb_threads, std::ref(counter)); 26: } 27: for (auto &t : threads) { 28: t.join(); 29: }
3.10. Bonne pratique : Eviter les variables mutables pour n'avoir que des variables non-mutables et patron d'architecture MapReduce
- ==> Eviter les variables mutables !
- ==> Piste de solution = Regarder si votre code ne pourrait pas
bénéficier du patron d'architecture MapReduce:
- Etape Map : Découpage en sous-problèmes et délégation des sous-problèmes à d'autres threads ou noeuds d'exécution (dans le cas d'une architecture répartie).
- Etape Reduce : Les threads/noeuds font remonter l'information au parent qui les avaient sollicités. Ce parent calcule le résultat.
- En environnement réparti, il est courant d'implémenter un MapReduce à l'aide d'un framework comme Hadoop.
3.11. Code 05 : Exemple de mise en oeuvre de MapReduce
- Le code présenté implémente un patron d'architecture MapReduce. Identifiez les étapes Map et Reduce.
12: void computeDecrement(const int nb_decrement, int& result) { 13: int totalDecrement = 0; 14: for (auto i = nb_decrement; i > 0; --i) { 15: ++totalDecrement; 16: } 17: result = totalDecrement; 18: } 19: 20: int main() { 21: auto counter = nb_count; 22: 23: const auto start = high_resolution_clock::now(); 24: const auto start_cpu = get_cpu_time(); 25: std::vector<std::jthread> threads(nb_threads); 26: std::vector<int> results(nb_threads); 27: int numThread = 0; 28: for (auto& t : threads) { 29: t = std::jthread(computeDecrement, nb_count / nb_threads, 30: std::ref(results[numThread])); 31: ++numThread; 32: } 33: numThread = 0; 34: for (auto& t : threads) { 35: t.join(); 36: counter -= results[numThread]; 37: ++numThread;
3.12. Outil : Tâche (future ou std::async())
Notions essentielles
- Lancement d'une tâche par
auto fut = std::async([] { resultat=calcul(); return resultat; }); - Attente du résultat d'une tâche par
resultat = fut.get();
[Grimm 2021] std::async should be your first choice : The C++ runtime decides if std::async is executed in a separate thread or not. The decision of the C++ runtime may depend on the number of CPU cores available, the utilization of your system, or the size of your work package. By using std::async you only specify the task that should run. The C++ runtime automatically manages the creation and also the lifetime of the thread.
Les CPP core guidelines disent aussi "CP.4: Think in terms of tasks, rather than threads."
- Toutefois,
https://www.boost.org/doc/libs/1_85_0/libs/fiber/doc/html/fiber/performance.html
montre que le launch d'un
std::asyncprend 106 us contre 52 us pour unstd::thread==> A voir si cette différence de performances est importante pour les utilisateurs.
3.13. Code 06 : Exemple d'utilisation de tasks
11: int taskDecrement(const int nb_decrement) { 12: int totalDecrement = 0; 13: for (auto i = nb_decrement; i > 0; --i) { 14: ++totalDecrement; 15: } 16: return totalDecrement; 17: } 18: 19: int main() { 20: auto counter = nb_count; 21: 22: const auto start = high_resolution_clock::now(); 23: const auto start_cpu = get_cpu_time(); 24: 25: /* auto fut0 = std::async([] { return taskDecrement(nb_count / nb_tasks); }); 26: auto fut1 = std::async([] { return taskDecrement(nb_count / nb_tasks); }); 27: auto fut2 = std::async([] { return taskDecrement(nb_count / nb_tasks); }); 28: auto fut3 = std::async([] { return taskDecrement(nb_count / nb_tasks); }); 29: counter -= fut0.get(); 30: counter -= fut1.get(); 31: counter -= fut2.get(); 32: counter -= fut3.get(); 33: */ 34: std::vector<std::future<int>> futures(nb_tasks); 35: for (auto& fut : futures) { 36: fut = std::async([] { return taskDecrement(nb_count / nb_tasks); }); 37: } 38: for (auto& fut : futures) { 39: counter -= fut.get(); 40: }
4. Spécificités C++
4.1. Outil : Lock
Notions essentielles
std::guarded_lockstd::scoped_lock- Pour verrouiller (et relâcher plusieur mutex à la fois)
std::unique_lock- Plus cher que
lock_guard, mais permet de reverrouiller récursivement un mutex. - Obligatoire pour variable condition (cf. Code 10) et quand concurrence avec std::shared_lock (cf. Code 20)
- Plus cher que
std::shared_lock==> Utilisation pour lecteurs-rédacteur (cf. Code 20)
4.2. Code 07 : S'appuyer sur la RAII pour déverrouiller automatiquement (notion spécifique C++)
Ce code montre comment éviter, grâce à la RAII, qu'un mutex reste
verrouillé si vous avez oublié l'instruction de déverrouillage ou bien
si une exception a eu lieu durant une section critique : nous nous
appuyons sur std::scoped_lock (depuis C++ 17).
12: void decrement(const int nb_decrement, int &counter) { 13: static std::mutex mtx; 14: for (auto i = nb_decrement; i > 0; --i) { 15: std::scoped_lock lock(mtx); // Since CPP 17 16: --counter; 17: }
4.3. Bonne pratique : Utilisation de variables static dans un Block scope
- Static variables with block scope are created exactly once and lazily. Lazily means that they are created just at the moment of usage.
- With C++11,static variables with block scope have an additional
guarantee, they are initialized in a thread-safe way. Warning:
Your compiler may not support this feature:
- For VisualStudio, since VS 2015, option /Zc:threadSafeInit (activated by default)
- For gcc, check if your compiler has option
-fno-threadsafe-statics(Cette option est là pour désactiver cette fonction. Donc, si elle est là, le compilateur implémente cette fonction.) - For clang, same as gcc.
4.4. Outil : thread_local (stockage spécifique à chaque thread)
- Permet d'avoir une variable statique qui n'est pas partagée par tous les threads.
- Quand on déclare une variable
thread_local, elle est implicitementstatic.
thread_local int v = 0;
4.5. Code 08 : Exemple d'utilisation de static et de thread_local
Ce code montre comment des variables sont partagées ou non par des
threads, selon leur lieu de déclaration et leur attribut static ou
thread_local.
12: void incr(std::atomic_int& v_main, int& v_work) { 13: static std::atomic_int v_incr_static = 0; 14: thread_local int v_incr_thread_local = 0; 15: int v_incr = 0; 16: ++v_main; 17: ++v_work; 18: ++v_incr_static; 19: ++v_incr_thread_local; 20: ++v_incr; 21: display(v_main, v_work, v_incr_static, v_incr_thread_local, v_incr); 22: } 23: 24: void work(std::atomic_int& v_main) { 25: int v_work = 0; 26: for (auto i = nb_times; i > 0; --i) { 27: incr(v_main, v_work); 28: } 29: } 30: 31: int main() { 32: std::atomic_int v_main = 0; 33: 34: std::vector<std::jthread> threads(nb_threads); 35: for (auto& t : threads) { 36: t = std::jthread(work, std::ref(v_main));
4.6. Code 09 : atomic ne peut pas être utilisé sur un std::vector
- Ce code ne compile pas avec
std::atomic<std::vector<int>>. - Il plante à l'exécution si on ne met pas de
mutex.
5. Multitâche pour gérer de multiples activités en parallèle
- Un programme peut gérer de multiples activités en parallèle sans que
ce soit forcément pour accélérer les performances. Par exemple :
- Un serveur http qui doit gérer les requêtes de multiples clients Web en parallèle.
- Un jeu qui gère la boucle de jeu en même temps que la tâche concernant l'IA.
- Ces multiples activités peuvent induire des problèmes de
synchronisation autre que l'exclusion mutuelle, donc la
spécification d'outils de synchronisation autres que le mutex/lock:
- Variable "Condition" (ou "moniteur")
- Variable "Sémaphore"
- Nous allons maintenant détailler ces outils et leurs déclinaisons.
6. Variables "Condition" ("Moniteur") pour de nouveaux patrons (patterns) de synchronisation
6.1. Outil : Variable "Condition" ("Moniteur")
Notions essentielles
- "Global" variables
std::mutex mtx; std::condition_variable condVar; bool dataReady{false};
- Le thread en attente exécute le code suivant :
// Code écrit // Code exécuté std::unique_lock<std::mutex> lck(mtx); std::unique_lock<std::mutex> lck(mtx); condVar.wait(lck, []{ return dataReady; }); while ( ![]{ return dataReady; }() { mtx.unlock(); condVar.wait(lck); mtx.lock(); }
- Le thread qui va débloquer la situation exécute le code suivant :
{
std::lock_guard<std::mutex> lck(mtx);
dataReady = true;
}
condVar.notify_one();
6.2. Code 10 : Pattern de synchronisation Cohorte à base de moniteur
- L'objectif de ce pattern de synchronisation est de garantir que
pas plus de N threads font un certain traitement.
- Parallèle avec la vie de tous les jours : Comment garantir qu'un parking de voitures de N places n'accueille pas plus de N véhicules ?
9: constexpr int max_cars_in_parking = 4; 10: constexpr int nb_threads = 10; 11: 12: void car_life(const int num_thread) { 13: static std::mutex mtx; 14: static std::condition_variable cond_var; 15: static int nb_cars_in_parking = 0; 16: 17: { 18: std::unique_lock lck(mtx); 19: std::cout << "Thread " << num_thread << " wants to enter parking" 20: << std::endl; 21: cond_var.wait(lck, [] { return nb_cars_in_parking < max_cars_in_parking; }); 22: ++nb_cars_in_parking; 23: } 24: std::cout << "Thread " << num_thread << " enters parking" << std::endl; 25: std::this_thread::sleep_for(200ms); 26: std::cout << "Thread " << num_thread << " exits parking" << std::endl; 27: { 28: std::lock_guard lck(mtx); 29: --nb_cars_in_parking; 30: } 31: cond_var.notify_one();
- Application : Considérez un parking avec seulement 2 places et 4
voitures qui arrivent (couleurs similaires aux couleurs des feutres
de tableau blanc) avec le scénatio suivant :
- Les voitures bleue et verte entrent dans le parking.
- La voiture rouge arrive et se retrouve en attente.
- La voiture bleue sort du parking juste au moment où la voiture
noire arrive ==> la voiture noire entre dans le parking avant même
que la voiture rouge ait pu amorcer un mouvement (et ce que le
cond_var.notify_one()soit hors ou dans la section critique).
- NB : Durant l'exécution, il se pourrait que vous obteniez des messages "mélangés". Par exemple :
Thread 6Thread 7 exits parking Thread 7 exited parking exits parking Thread 6 exited parking
- Ceci est juste un mélange d'affichages qui ne remet pas en cause la
synchronisation qui, elle, s'est bien passée. Pour éviter ce
mélange, une 1ère solution : vous définissez un mutex global qui
protège chaque
cout(cf. exemple en13_SyncPattern_Barrier):
void synchronizedOut(const std::string& s) noexcept { static std::mutex coutMutex; std::scoped_lock lock(coutMutex); std::cout << s; } // Invocation par synchronizedOut(name + ": " + "Morning work done!\n");
- Soit, 2ème solution (depuis C++ 20) : vous vous appuyez sur
std::basic_osyncstreamen écrivant par exemple:
std::osyncstream(std::cout) << "Hello, " << "World!" << std::endl;
6.3. Code 11 : Pattern de synchronisation Loquet (Latch) avec moniteur (N threads contrôlent 1 thread)
- Problème résolu : 8 passagers d'un minibus doivent embarquer dedans. Le conducteur ne démarre que quand tout le monde a embarqué.
10: constexpr int minibus_capacity = 8; // passengers (in addition to the driver) 11: 12: struct minibus_t { 13: std::mutex mtx; 14: std::condition_variable cond_var; 15: int nb_passengers{0}; // Already boarded in minibus 16: }; 17: 18: void passenger(const int num_passenger, minibus_t& minibus) { 19: std::osyncstream(std::cout) 20: << "Passenger " << num_passenger << " starting to board" << std::endl; 21: std::this_thread::sleep_for(1s); std::osyncstream(std::cout) 22: << "Passenger " << num_passenger << " is done boarding" << std::endl; 23: { 24: std::lock_guard lck(minibus.mtx); 25: ++minibus.nb_passengers; 26: } 27: minibus.cond_var.notify_one(); 28: } 29: 30: void driver(minibus_t& minibus) { 31: std::osyncstream(std::cout) << "Driver waiting for " << minibus_capacity 32: << " passengers to get onboard" << std::endl; 33: { 34: std::unique_lock lck(minibus.mtx); 35: minibus.cond_var.wait(
- Dans ce code, nous utilisons
notify_one(). Aurions-nous pu utilisernotify_all? Si oui, lequel des deux est le plus performant ? - NB : Vu que les passagers terminent leur exécution une fois qu'ils
ont embarqués, nous aurions pu procéder comme au "Code 06",
programmer les passagers sous forme de
std::async(), le chauffeur faisant desget()sur chacun des passagers.
6.4. Code 12 : Pattern de synchronisation Loquet (Latch) avec moniteur (1 thread contrôle N threads)
- Problème résolu : 8 coureurs d'athlétisme ne commencent à courir que
quand le juge a donné le top départ.
- Dans la version fournie, le juge donne le signal de début de course une fois que les coureurs sont en place.
- Une fois que vous avez vérifié que cette version fonctionne,
mettez le
sleep_foravant lefor (auto& t : threads) {et le lancement du referee avant lesleep_for. Vérifiez que les coureurs se mettent bien à courir immédiatement, vu que le signal a déjà été donné.
10: constexpr int nb_runners = 11: 8; // How many runners can run in parallel in a stadium 12: 13: struct stadium_t { 14: std::mutex mtx; 15: std::condition_variable cond_var; 16: bool run_signal{false}; 17: }; 18: 19: void runner(const int num_runner, stadium_t& stadium) { 20: std::osyncstream(std::cout) 21: << "Runner " << num_runner << " waiting for run signal" << std::endl; 22: { 23: std::unique_lock lck(stadium.mtx); 24: stadium.cond_var.wait(lck, [&stadium] { return stadium.run_signal; }); 25: } 26: std::osyncstream(std::cout) 27: << "Runner " << num_runner << " starts running" << std::endl; 28: } 29: 30: void referee(stadium_t& stadium) { 31: std::osyncstream(std::cout) 32: << "Referee is about to fire run signal" << std::endl; 33: { 34: std::lock_guard lck(stadium.mtx);
- Dans ce code, nous utilisons
notify_all(). Selon vous, aurions-nous pu utilisernotify_one?
6.5. Outil : std::latch
Notions essentielles [Grimm, 2021]
| Member function | Description |
|---|---|
lat.count_down(upd = 1) |
Atomically decrements the counter by upd without blocking the caller. |
lat.try_wait() |
Returns true if counter == 0. |
lat.wait() |
Returns immediately if counter = 0. If not blocks until counter = 0. |
lat.arrive_and_wait(upd = 1) |
Equivalent to count_down(upd); wait(); |
std::latch::max |
Maximum value of the counter supported by the implementation |
6.6. Code 13 : Pattern de synchronisation Loquet (Latch) avec std::latch (N threads contrôlent 1 thread)
11: void passenger(const int num_passenger, std::latch& onboarding_remaining) { 12: std::osyncstream(std::cout) 13: << "Passenger " << num_passenger << " starting to board" << std::endl; 14: std::this_thread::sleep_for(1s); 15: std::osyncstream(std::cout) 16: << "Passenger " << num_passenger << " is done boarding" << std::endl; 17: onboarding_remaining.count_down(); 18: } 19: 20: void driver(const std::latch& onboarding_remaining) { 21: std::osyncstream(std::cout) << "Driver waiting for " << minibus_capacity 22: << " passengers to get onboard" << std::endl; 23: onboarding_remaining.wait(); 24: std::osyncstream(std::cout) 25: << "Driver sees that " << minibus_capacity 26: << " passengers are onboard: He can start the trip!" << std::endl;
6.7. Code 14 : Pattern de synchronisation Loquet (Latch) avec std::latch (1 thread contrôle N threads)
11: 8; // How many runners can run in parallel in a stadium 12: 13: void runner(const int num_runner, const std::latch& fire_signal) { 14: std::osyncstream(std::cout) 15: << "Runner " << num_runner << " waiting for run signal" << std::endl; 16: fire_signal.wait(); 17: std::osyncstream(std::cout) 18: << "Runner " << num_runner << " starts running" << std::endl; 19: } 20: 21: void referee(std::latch& fire_signal) { 22: std::osyncstream(std::cout) 23: << "Referee is about to fire run signal" << std::endl; 24: std::osyncstream(std::cout) << "Referee has fired run signal" << std::endl; 25: fire_signal.count_down();
Une fois que vous avez vérifié que la version fournie fonctionne,
mettez le sleep_for avant le for (auto& t : threads) { et le
lancement du referee avant le sleep_for. Vérifiez que les
coureurs se mettent bien à courir immédiatement, vu que le signal
a déjà été donné.
6.8. Outil : std::barrier
Notions essentielles [Grimm, 2021]
- A
std::barrieris similar to astd::latch - But two differences
- You can use a
std::barriermore than once - You can adjust the counter for the next phase
- You can use a
| Member function | Description |
|---|---|
bar.arrive(upd) |
Atomically decrements counter by upd. |
bar.wait() |
Blocks at the synchronization point until the completion step is done. |
bar.arrive_and_wait() |
Equivalent to wait(arrive()) |
bar.arrive_and_drop() |
Decrements the initial expected count for all subsequent phases by one. |
std::barrier::max |
Maximum value of the counter supported by the implementation. |
6.9. Code 15 : Pattern de synchronisation Barrière (Latch) avec std::barrier
6.10. Pattern de synchronisation Producteur / Consommateur
6.10.1. Enoncé du problème à résoudre
- 1 ou plusieurs threads produisent des données.
- 1 ou plusieurs threads consomment les données produites.
2 variantes
- La communication se fait via un buffer de taille infinie (la production n'est donc pas limitée).
- La communication se fait via un buffer , ne pouvant contenir qu'un maximum de N data.

6.10.2. Variante avec buffer de taille infinie (cf. Code 16)
- Cette variante présente le risque de consommer trop de mémoire, si les producteurs produisent beaucoup plus vite que les consommateurs ne consomment.
6.10.3. Variante avec buffer de taille finie
nb_places_dispo = N; nb_data_dispo = 0; slot_dispo = 0; slot_data = 0; // Producteur // Consommateur Répéter Répéter data = produitData(); mtx_places_dispo.lock(); mtx_data_dispo.lock(); cond_places_dispo.wait( mtx_places_dispo, cond_data_dispo.wait( data_dispo, []{ return nb_places_dispo > 0 }); []{ return nb_data_dispo > 0 }); --nb_place_dispo; --nb_data_dispo; buffer[slot_dispo] = data; data = buffer[slot_data]; slot_dispo = (slot_dispo + 1) % N; slot_data = (slot_data + 1) % N; mtx_places_dispo.unlock(); mtx_data_dispo.unlock(); mtx_data_dispo.lock(); mtx_places_dispo.lock(); ++nb_data_dispo; ++nb_place_dispo; mtx_data_dispo.unlock(); mtx_places_dispo.unlock(); cond_data_dispo.notify_one(); cond_place_dispo.notify_one(); consomme(data); Fin Répéter Fin répéter
- Selon vous, pourquoi doit-on avoir la mise à jour de slot_dispo et
de slot_data dans une section critique ? Pourquoi définir ces
variables comme
atomicne suffit pas ?
6.10.4. Variante (fausse) avec buffer de taille finie
nb_places_dispo = N; nb_data_dispo = 0; slot_dispo = 0; slot_data = 0; // Producteur // Consommateur Répéter Répéter mtx_places_dispo.lock(); mtx_data_dispo.lock(); cond_places_dispo.wait( mtx_places_dispo, cond_data_dispo.wait( data_dispo, []{ return nb_places_dispo > 0 }); []{ return nb_data_dispo > 0 }); --nb_place_dispo; --nb_data_dispo; slot = slot_dispo; slot = slot_data; slot_dispo = (slot_dispo + 1) % N; slot_data = (slot_data + 1) % N; mtx_places_dispo.unlock(); mtx_data_dispo.unlock(); buffer[slot] = calculData(); data = (buffer[slot]); mtx_data_dispo.lock(); mtx_places_dispo.lock(); ++nb_data_dispo; ++nb_place_dispo; mtx_data_dispo.unlock(); mtx_places_dispo.unlock(); cond_data_dispo.notify_one(); cond_place_dispo.notify_one(); consomme(data); Fin Répéter Fin répéter
- Pourquoi cette variante pose-t-elle problème ?
6.11. Code 16 : Pattern de synchronisation Producteur / Consommateur avec queue illimitée
- Ce code largement inspiré du livre [Grimm, 2021] s'appuie sur une queue non limitée en taille. Notez que le livre [Grimm, 2021] contient, aux pages 538-554, toute une discussion sur l'implémentation d'une telle queue.
- Vu tous les warnings remontés par SonarLint, la qualité de ce code pose question.
6.12. Code 17 : Pattern de synchronisation Producteur / Consommateur avec production régulée
- Ce code implémente l'algorithme présenté précédemment.
- Notez l'instruction
exit(0);qui permet de forcer l'arrêt du processus, même si des threads détachés continuent à s'exécuter (Mettez cette instruction en commentaire, puis relancez votre programme pour vous en convaincre).
7. Variables semaphore pour une autre manière de synchroniser
7.1. Outil : Sémaphores
Notions essentielles
- Historiquement, les sémaphores ont été conçus avant les moniteurs. Mais, comme de nombreuses personnes estiment qu'il est plus simple de travailler avec les moniteurs qu'avec les sémaphores, les moniteurs ont été offerts dès C++ 11 alors que les sémaphores ne sont arrivés qu'avec C++ 20.
- Notions de base
- Un sémaphore est un objet système contenant
- Un compteur initialisé à une certaine valeur
- Une file d'attente de processus mis en attente car le compteur avait une valeur < 0.
- Opérations
- Initialisation :
std::counting_semaphore<valeur_init> sem(valeur_init); - Opérateur
P()("Puis-je ?") :sem.acquire(); // en C++ - Opérateur
V()("Vas-y !") :sem.release(); // en C++
- Initialisation :
- Un sémaphore est un objet système contenant
// P() // V() Si compteur <= 0 Alors compteur += 1 Met le thread en attente Réveille l'éventuel thread en tête de file d'attente FinSi compteur -= 1
- Bonnes pratiques
- Un sémaphore initialisé à 1 peut être utilisé comme un
mutex. Mais, préférez systématiquement le mutex si opérations
lock() et unlock() sont faites dans le même thread. En effet :
- Mutex plus performant que sémaphore.
- Code plus clair ==> Meilleure maintenabilité.
- Un sémaphore initialisé à 1 peut être utilisé comme un
mutex. Mais, préférez systématiquement le mutex si opérations
lock() et unlock() sont faites dans le même thread. En effet :
7.2. Code 18 : Pattern de synchronisation Cohorte à base de sémaphore
12: void car_life(const int num_thread) { 13: static std::counting_semaphore<max_cars_in_parking> parking( 14: max_cars_in_parking); 15: std::osyncstream(std::cout) 16: << "Thread " << num_thread << " wants to enter parking" << std::endl; 17: parking.acquire(); 18: std::osyncstream(std::cout) 19: << "Thread " << num_thread << " enters parking" << std::endl; 20: std::this_thread::sleep_for(0.2s); // Note: We do not use sleep, otherwise
7.3. Pattern de synchronisation Rendez-vous
On souhaite que, après un travail, 2 threads se "rejoignent" avant de démarrer un nouveau travail.
sem_juliette(0) sem_romeo(0) // Juliette // Romeo Se pouponner(); Encore plus se pouponner() sem_juliette.release() sem_romeo.release() sem_romeo.acquire() sem_juliette.acquire() Boire un pseudo-poison() Être perclus de douleur()
Notez qu'un std::latch() permet d'être plus concis (et plus efficace ?) :
std::latch rdv(2); // Car 2 personnes ont besoin de se retrouver. // Juliette // Romeo Se pouponner(); Encore plus se pouponner() rdv.arrive_and_wait() rdv.arrive_and_wait() Boire un pseudo-poison() Être perclus de douleur()
7.4. Pattern de synchronisation Lecteurs-Rédacteurs
7.4.1. Enoncé du problème
(cf. https://www.tutorialspoint.com/readers-writers-problem)
The readers-writers problem relates to an object such as a file that is shared between multiple processes. Some of these processes are readers i.e. they only want to read the data from the object and some of the processes are writers i.e. they want to write into the object.
The readers-writers problem is used to manage synchronization so that there are no problems with the object data. For example - If two readers access the object at the same time there is no problem. However if two writers or a reader and writer access the object at the same time, there may be problems.
To solve this situation, a writer should get exclusive access to an object i.e. when a writer is accessing the object, no reader or writer may access it. However, multiple readers can access the object at the same time.
7.4.2. Algorithmes
Notez l'utilisation de mutex ou de sémaphore selon qu'on lock()/unlock() dans le même thread ou pas.
std::semaphore sem_wrt(1); int nb_reader(0); // Reader // Writer mtx_reader.lock(); sem_wrt.acquire(); ++nb_reader; . if (nb_reader == 1) WRITE INTO THE OBJECT sem_wrt.acquire(); . mtx_reader.unlock(); sem_wrt.release(); . . READ THE OBJECT . mtx_reader.lock(); --nb_reader; if (nb_reader == 0) sem_wrt.release(); mtx_reader.unlock();
7.4.3. Risque de famine pour le writer
Les algorithmes précédents présentent un risque de famine : s'il y a de nombreux lecteurs, ils risquent d'empêcher indéfiniment qu'un rédacteur prenne la main.
On pourrait faire un diagramme de temps. Mais il est plus ludique de demander de l'aide à Gudul, Symfony et Petit Poney.
Solution : Ajouter un autre mutex_anti_famine.
7.4.4. Algorithmes corrigeant le problème de famine
On ajoute un mutex (vu que lock()/unlock() dans le même thread) qui permet d'ordonancer ceux qui veulent accéder à l'objet.
std::semaphore sem_wrt(1); int nb_reader(0); // Reader // Writer mtx_glob.lock(); mtx_glob.lock(); mtx_reader.lock();//Désormais inutile sem_wrt.acquire(); ++nb_reader; . if (nb_reader == 1) WRITE INTO THE OBJECT sem_wrt.acquire(); . mtx_reader.unlock();//Désormais inutile sem_wrt.release(); mtx_glob.unlock(); mtx_glob.lock(); . . READ THE OBJECT . mtx_reader.lock(); --nb_reader; if (nb_reader == 0) sem_wrt.release(); mtx_reader.unlock();
- Pourquoi les instructions
mtx_reader.lock()etmtx_reader.unlock()ont le commentaire//Désormais inutile? - Pourquoi les instructions
wrt.lock()etwrt.unlock()du Writer restent nécessaires ?
7.5. Code 19 : Pattern de synchronisation Lecteurs-Rédacteurs avec sémaphore
Analysez le code et posez des questions si des points vous semblent obscurs.
7.6. Outil : Verrou pour lecteurs-rédacteur (std::shared_lock)
Notions essentielles
std::shared_locks'appuie sur unstd::shared_timed_mutex(C++14) ou unstd::shared_mutex(C++17), le premier permettant de spécifier une date de libération ou une durée avant libération.- Ensuite
- Verrou de lecteur :
std::shared_lock readerLock(a_shared_mutex); - Verrou de rédacteur :
std::lock_guard writerLock(a_shared_mutex);
- Verrou de lecteur :
7.7. Code 20 : Pattern de synchronisation Lecteurs-Rédacteurs avec verrou lecteurs-rédacteur
Analysez le code. Voyez comment l'utilisation du verrou lecteurs-rédacteur simplifie le code. Posez des questions si des points vous semblent obscurs.
8. Autres notions importantes
8.1. Bonne pratique : Gestion de la mémoire (allocation/désallocation)
Notions essentielles
- Si un programme multithreadé fait des allocations/désallocations mémoire, il est possible que
- les allocations se font dans un thread,
- les utilisations de la mémoire allouée se fait dans d'autres threads,
- les désallocations se fait dans un autre thread.
- Cela entraine plein de questions dont :
- Comment synchroniser allocations, utilisation et désallocations ?
- Comment être sûr qu'on n'oublie pas de libérer de la mémoire ?
- Comment détecter si, par erreur de logique, notre code utilise de la mémoire mémoire déjà libérée ?
- Les réponses à ces questions dépendent du langage :
- Langages à base de garbage collector (C#, Java) : a priori, rien à faire.
- En C, il est essentiel de respecter les conseils suivants :
- Si vous déclarez un pointeur nu, pensez à systématiquement
l'initialiser (à
NULLsi vous n'avez pas de valeur à fournir à la variable). - Tout
free(ptr)doit être suivi deptr = NULL;
- Si vous déclarez un pointeur nu, pensez à systématiquement
l'initialiser (à
- En C++, s'appuyer sur
shared_ptr, en réfléchissant préalablement s'il est nécessaire d'avoir des pointeurs. cf. Exemple d'un serveur TCP.
8.2. Code 21 : Serveur TCP avec shared_ptr
NB : Dans ce code, remarquez qu'au lieu d'une exclusion mutuelle dans l'accès à l'objet socket, on aurait pu mettre en place un lecteurs-rédacteurs. Mais la diffusion obtenue n'aurait plus été à ordre total.
8.3. Code 22 : Serveur TCP avec unique_ptr
8.4. Code 23 : Serveur TCP sans pointeurs
TODO Ajouter ce code
8.5. Outil : Thread-safe initialisation
8.5.1. (std::call_once and std::once_flag)
8.6. Outil : Algorithmes parallèles de la STL (Standard Template Library, C++17)
Notions essentielles
- The Standard Template Library has more than 100 algorithms for searching, counting, and manipulating ranges and their elements. With C++17, 69 of them get new overloads, and eight new ones are added. The overloaded, and new algorithms can be invoked with a so-called execution policy.
- Using an execution policy, you can specify whether the algorithm
should run sequentially, in parallel,or parallel with
vectorization. For using the execution policy,you have to include
the header
<execution> - The execution policy is a permission and not a requirement.
std::execution::seq: runs the program sequentiallystd::execution::par: runs the program in parallel on multiple threadsstd::execution::par_unseq: runs the program in parallel on multiple threads and allows the interleaving of individual loops; permits a vectorised version with SIMD (Single Instruction Multiple Data) extensions.
- Attention : The parallel algorithm does not automatically protect you from data races and deadlocks.
8.7. Code 24 : Algorithmes parallèles de la STL et execution policy
8.8. Code 25 : Algorithmes parallèles de la STL et risque de Data Race
8.9. Outil : Coroutines (C++ 20)
Notions essentielles
- Les coroutines sont une mise en oeuvre d'un paradigme producteur-consommateur avec :
- Un producteur (la coroutine)
- Un consommateur (le thread qui crée la coroutine)
- Ils communiquent via un buffer
- limité à 1 seul élément
- capable de transporter aussi les exceptions remontées par la coroutine
- Les coroutines sont une généralisation des tâches.
8.10. Code 26 : Coroutine
8.11. Fibres
- Les fibres sont des unités d'exécution qui s'exécutent au sein de
threads, sans préemption entre fibres (un fibre doit explicitement
passer la main à une autre fibre,
cf. https://learn.microsoft.com/fr-fr/windows/win32/procthread/fibers).
- "A context switch between threads costs usually thousands of CPU cycles on x86 compared to a fiber switch with less than 100 cycles." (cf. doc fibres Boost)
- ==> Pas mal utilisé dans le jeu vidéo
- Pour approfondir
- https://agraphicsguynotes.com/posts/fiber_in_cpp_understanding_the_basics/
- Boost.Fiber fournit une bibliothèque de fibres pour les applications C++.
- TODO A compléter !
8.12. Debug, Profiling
- Debug
- TODO : Démo de Debug avec multithreading.
- Profiling: Comprendre où un programme passe du temps.
- https://hackingcpp.com/cpp/tools/profilers.html recommande VTune d'Intel, outil également recommandé par https://stackoverflow.com/questions/67554/whats-the-best-free-c-profiler-for-windows
- Chez ASOBO, ils utilisent Microsoft PIX qui concerne "Performance tuning and debugging for DirectX 12 games on Windows"
8.13. What should come in C++ 23
TODO To be continued ! (lisez [Grimm, 2021] si vous êtes impatient(e))
9. Threads versus Autres modèles de programmation
- Jusqu'à présent, nous avons travaillé avec des applications
multithreadées, ce multithread étant préemptif : Quand un thread
s'exécute, il peut être interrompu à n'importe quel moment
par un autre thread.
- Cela nécessite de gérer d'éventuels problèmes de synchronisation (cf. tout ce que nous avons vu jusqu'à présent.
- Il existe aussi :
- des modèles de threads non-préemptifs (Quand un thread
s'exécute, il doit explicitement passer la main - instruction
yieldpour qu'un autre prenne la main).- cf. notion de fibre informatique
- cf. article Robust C++: P and V Considered Harmful et son framework associé.
- des modèles de programmation basés sur de la programmation
événementielle (programmation asynchrone).
- Livre "Development and Deployment of Multiplayer Online Games", Volume 2, chapitre 5 "(Re)actor-Fest architecture. It just works."
- Boost for Event-Driven Program (Langage C++)
- https://libevent.org/ (langage C)
- des modèles de programmation où il faut explicitement "donner la main" à une bibliothèque en appelant une de ses fonctions pour que cette bibliothèque puisse progresser (cf., par exemple, SDL/Bibliothèques Photon et GGPO).
- des modèles de threads non-préemptifs (Quand un thread
s'exécute, il doit explicitement passer la main - instruction
10. Conclusion
La programmation concurrente est une combinaison de :
- Outils
volatile(variablevolatile)- Thread
- Diagramme de séquence
- Mutex et Lock
- Variables
atomic - Tâches (future ou
std::async()) - Condition/Moniteur (
std::condition) std::latchstd::barrier- Sémaphores
std::shared_lock- Thread-safe initialization
- Algorithmes parallèles de la STL
- Coroutines
- Patterns de synchronisation
- Exclusion mutuelle
- Cohorte
- Loquet (Latch)
- Barrière
- Rendez-vous
- Producteur/Consommateur
- Lecteurs-rédacteurs
- Bonnes pratiques
- Eviter les variables mutables pour n'avoir que des variables non-mutables et patron d'architecture MapReduce
- Utilisation de variables static dans un Block scope
- Dès que possible, préférer les mutex aux sémaphores initialisés à 1
- "Trucs" pour la gestion de la mémoire (allocation/désallocation)
Il existe d'autres modèles de programmation.
11. Bibliographie
- "Concurrency with Modern C++, What every professional C++
programmer should know about concurrency.", Rainer Grimm, Juillet
2021, https://leanpub.com/concurrencywithmodernc
- Un livre payant, mais excellent.
- https://www.modernescpp.com/index.php/category/multithreading, Rainer Grimm, le blog de l'auteur du livre évoqué précédemment.
- "The Little Book of Semaphores", Allen B. Downey, 2016,
https://greenteapress.com/wp/semaphores/
- Un livre gratuit qui est une mine d'information sur les problèmes de stnchronisation.
- "My tutorial and take on C++20 coroutines", David Mazières, Février
2021, https://www.scs.stanford.edu/~dm/blog/c++-coroutines.html
- Explique bien les coroutines C++ 20.
- "C++ Concurrency in_Action, Practical multithreading", Anthony
Williams, 2012.
- ne concerne que C++ 11 et me semble désormais obsolète.
12. Remarques de relecture sur ce cours
Cette section liste les remarques de relecture (faites par des professionnels, anciens JIN) sur l'édition du 10/10/2021 de ce cours, remarques que Michel Simatic n'a pas encore eu le temps d'intégrer dans les différentes sections ci-dessus de ce cours.
Elles permettent de compléter utilement ce cours, afin de permettre au lecteur d'aller toujours plus loin ("Vers l'infini et au delà", bien évidemment !)
12.1. Remarques d'Ada Couprié-Diaz (12/10/2021)
Je pourrais pinailler sur quelques éléments mais ça ne serait pas très utile (bien que ce que tu dis sur la fréquence dans 3.1.1 est juste, ça passe sous le tapis et ignore divers discussions et problèmes très intéressants ! Mais je nage là dedans, je suis biaisé. Aussi, j'ai compté 8 instructions dans la boucle du 3.1.1 :) ).
Ma remarque principale c'est l'absence de Thread Sanitizer, l'outil d'instrumentation de Google pour justement détecter les data races et autres joyeusetés du multithreading. Je remarque qu'il est malheureusement pas disponible sur MSVC, mais ça reste un outil puissant dans ce domaine.
Je n'ai pas trop le temps de chercher en détail non plus mais je suis surpris que les fonctionnalités C++ soient considérées notablement plus lentes que le passage par la machinerie système; je te fais confiance. (Même si à première vue je vois passer des futex pthread par la lib standard)
Un autre élément qui pourrait être rapidement évoqué (je ne sais pas si c'est le cas sur la partie cours) c'est le problème de "thundering herd" dans le cas 1 contrôle N thread. Le problème est en particulier pour une groupe de thread en attente de tâche à traiter, qui peuvent tous être réveillés à la moindre arrivée de travail qui ne peut finalement être récupérée que par un nombre limité de threads. Ça peut avoir un impact fort sur la performance système général et réduire le débit du programme.
Vis-à-vis des atomics, tu soulignes qu'il y a des instructions CPU dédiées, il y en a aussi pour certains types de verrou et pour la plupart des barrières ! Leur utilisation dépend beaucoup de la bibliothèque C++ utilisée et peut parfois être faite directement par des fonctions fournies par le compilateurs (intrinsics). C'est d'ailleurs parfois ces mêmes fonctions qui servent à implémenter d'autres primitives de synchronisation.
Il me semble que les codes 24 et 25 ne sont pas finaux mais il manque à l'heure actuelle -ltbb dans les options de link Vis-à-vis de clang la plupart des exemples compilent, avec l'exception notable des coroutines vu qu'il est encore capricieux à ce sujet : le header est différent, le namespace aussi et il faut (dans une majorité des cas) forcer le changement de bibliothèque standard à la compilation… Peu agréable pour le moment, et comme tu le soulignes Clang est à la traîne sur l'implémentation des standards.
Une chose intéressante que tu ne mentionnes pas non plus vis-à-vis de la performance des variables partagées sur des threads c'est que ça peut entraîner des invalidations de cache assez régulièrement. Ce n'est pas toujours un problème en soit, mais ça peut l'être.
Vis à vis du profiling : je ne sais pas si c'est disponible sous Windows, mais sous Linux il est possible de profiler en multithread avec CLion et obtenir des "flame graphs" ainsi qu'un arbre d'appels. Ce n'est pas inutile, bien que moins poussé que ce que fourni Microsoft avec Visual Studio (Il faut bien rendre à César ce qui est à César)
J'ai oublié un truc sur 3.1.1 : pour Linux la façon la plus portable de lire la fréquence est cat /proc/cpuinfo | grep Hz . Il faut noter que la fréquence de chaque cœur apparaîtra, ainsi que la fréquence de base du processeur. On pourra remarquer qu'elles ne sont pas forcément égales, ni celles de différents cœurs entre eux. C'est tout ce qui me vient @Michel Simatic (Au cas où le thread soit passé inaperçu :) ) en espérant que ça te soit utile. Je trouve en tout cas que c'est vraiment une introduction et référence super à avoir ! (En bonus implémenter un compteur sous verrou en pur assembleur est un exercice intéressant pour ceux qui voudraient un bon challenge 😄 J'avoue cependant que je ne connais pas la faisabilité en x86_64, je l'ai fait en A64 pour pratiquer)
12.2. Remarques de Xavier Niochaut (15/10/2021)
Dans la liste des techniques non-préemptives, j'ajouterais les coroutines, qui sont très proches des fibres (si ce n'est la même chose selon la définition).
Je rajoute juste un point sur les coroutines :
- Cet article explique très bien comment elles fonctionnent. https://www.scs.stanford.edu/~dm/blog/c++-coroutines.html
- Je me suis basé dessus pour l'implémentation des coroutines de mon moteur personnel. Avec un peu d'aide de cppcoro pour comprendre des points précis : https://github.com/lewissbaker/cppcoro
- En revanche j'ai peur que les coroutines soient un peu trop compliquées à implémenter soit même quand on débute le C++ (donc cppcoro pourrait être intéressant à utiliser). Ça peut être une idée pour une prochaine itération du cours :-)