ResourceRequest.
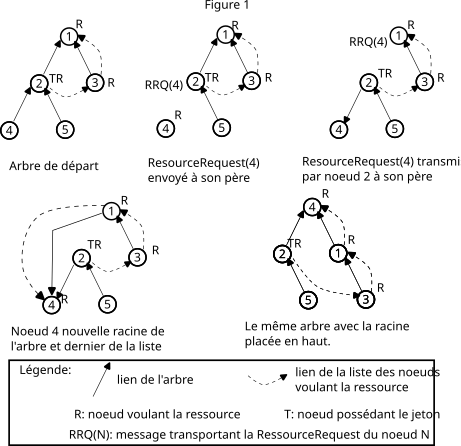
Dans ce sujet, nous mettons en œuvre l'algorithme de Naimi-Tréhel qui assure un mécanisme d'exclusion mutuelle dans un système réparti. Pour un système de N éléments, la demande de la ressource critique est gérée avec en moyenne Log(N) messages. C'est un algorithme à jeton qui suppose aucune défaillance (aucune perte de message, aucune défaillance des N éléments du système). Pour écrire ce programme, vous n'êtes pas obligé de comprendre les détails de l'algorithme (l'énoncé détaille chacune des étapes de l'algorithme lorsqu'il demande de les mettre en œuvre), mais une compréhension générale de l'architecture globale du système est très utile.
Les N éléments forment deux structures qui vont évoluer au cours des échanges de messages :
Toutes les fois qu'un nœud veut obtenir la ressource en exclusion mutuelle, l'algorithme transforme l'arbre et la liste de façon à ce que ce nœud devienne la nouvelle racine de l'arbre ainsi que le dernier élément de la liste. Pour illustrer le principe de l'algorithme, regardons ce qui se passe lorsqu'un nœud réclame la ressource à partir de la situation initiale de la figure 1 ci-dessous :
ResourceRequest
(« RRQ(4) » sur la figure) vers son
père et se détache de l'arbre pour se préparer à devenir la
nouvelle racine. L'algorithme remonte le
message ResourceRequest jusqu'à la racine et tous
les nœuds sur ce chemin prennent pour père l'émetteur
du ResourceRequest (ici le nœud 4). Sur le
deuxième schéma le RRQ(4) est arrivé dans la file
d'attente TCP du nœud 2, mais n'est pas encore
traité par le nœud 2 ;
ResourceRequest à son ancien père, et
ensuite a pris le nœud 4 pour père ;
ResourceRequest est arrivé à la racine,
qui est aussi le dernier de la liste. Ce nœud cède ces deux
rôles en prenant pour père le nœud 4 et en se
positionnant l'avant dernier dans la liste chaînée (il ajoute
le nœud 4 à la fin de la liste) ;
ResourceRequest.
Donc, en résumé, la demande de ressource émise par le nœud 4 a placé ce dernier à la racine de l'arbre et en dernier sur la liste. Le jeton n'a pas changé de propriétaire. Voyons maintenant la partie de l'algorithme qui gère ce changement du propriétaire du jeton.
Lorsque le nœud possédant le jeton n'a plus besoin de la ressource, il transmet le jeton au suivant de la liste chaînée et quitte la liste chaînée (cf. figure 2) :
Token) au suivant sur la liste. Il perd
donc aussi l'étiquette T. Après cette action, le
nœud 2 n'est plus dans la liste chaînée, c'est-à-dire
qu'il ne réclame plus la ressource. Notez aussi que plus
aucun nœud ne possède le jeton (pas d'étiquette T),
car il est actuellement dans le message Token
dans le file d'attente TCP du nœud 3 ;
Token.
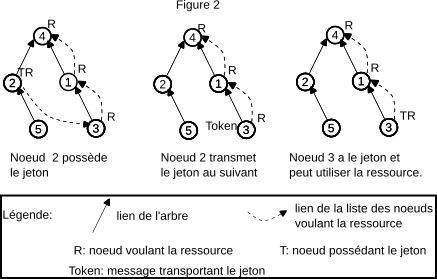
Enfin, regardons le cas particulier où la liste est réduite à un
seul nœud : il est donc à la fois le premier de la liste (il
possède le jeton), et le dernier de la liste (il est la racine de
l'arbre). Lorsque ce nœud libère la ressource, il n'y a plus de
nœud suivant sur la liste à qui transmettre le jeton. Dans ce cas,
le nœud conserve le jeton pour le transmettre au nœud émetteur du
premier message ResourceRequest qu'il recevra. Cela
maintient la troisième propriété énoncée plus haut : si
aucun nœud n'utilise la ressource, c'est le nœud racine qui
conserve le jeton.
Vous disposer de 3h pour réaliser ce TP. Vous avez le droit aux documents suivants :
JAVA ≥ 17.
Pour installer le sujet :
En fin de TP :
La classe représentant un nœud est la
classe tsp.csc4509.tpnote.Node. Dans la suite de ce
sujet, nous désignons les nœuds par le
terme Node. Chaque Node
du réseau est un élément de l'arbre, et éventuellement, s'il
demande la ressource, un élément de la liste chaînée. Du point de
vue de la programmation réseau JAVA NIO,
un Node est un serveur TCP de tous
ses fils dans l'arbre et un serveur TCP de son
prédécesseur dans la liste chaînée. Et, par symétrie, il est un
client TCP de son père dans l'arbre et un
client TCP du suivant dans la liste chaînée.
Chaque Node est piloté par
une Console, une différente pour
chaque Node. Elle sert à le contrôler (quand
réclame-t-il la ressource et pour combien de temps ?). Du
point de vue du réseau, la Console est un
client TCP du Node.
Enfin, pour simuler la ressource, un gestionnaire de
ressource TaskServer (unique) est prêt à
accepter la connexion des Nodes (mais une
seule à un instant donné). Le TaskServer
réalise une tâche qui, pour ce TP, se résume à l'appel
de Thread.sleep(). Le TaskServer
est donc un serveur TCP des Nodes.
Tous les messages échangés entre ces éléments sont des objets Java
sérialisés, et nous utilisons la
classe FullDuplexMsgWorker écrite et utilisée durant
les TPs pour faire ces échanges.
La liste des classes composants cette architecture réseau est donc :
tsp.csc4509.tpnote.Node : classe représentant un
nœud. L'essentiel du code à écrire pour ce TP se trouve dans
cette classe ;
tsp.csc4509.tpnote.TaskServer : classe
représentant la ressource critique à partager. Cette classe
doit être écrite en quasi totalité ;
tsp.csc4509.appli.Console : classe
contrôlant chaque nœud pour
réaliser les tests d'intégration. Le code de cette classe est
totalement fourni.
La liste des types des messages se trouve dans
l'énumération tsp.csc4509.tpnote.MessType. On y
trouve :
TASKREQUESTTYPE : le type des messages
transportant un objet TaskRequest qui est
envoyé par la Console
au Node, et ensuite, lorsque
le Node obtient le jeton,
du Node
au TaskServer ;
RESOURCEREQUESTTYPE : le type des messages
transportant un objet ResourceRequest qui
est transmis de Node
en Node jusqu'au nœud racine, comme nous
l'expliquons dans l'introduction de ce sujet ;
TOKENTYPE : le type des messages
transportant un objet Token envoyé par
un Node vers le Node
suivant de la liste chaînée quand il libère la
ressource ;
TASKRESPONSETYPE : le type des messages
transportant un objet TaskResponse émis
par le TaskServer vers
un Node une fois la tâche terminée, et qui
est ensuite transmis par le Node à
sa Console.
Chaque Node de l'arbre est identifié grace à
un NodeId (unique donc pour
chaque Node). Ce NodeId est aussi
le paramètre des ResourceRequests pour
identifier le Node émetteur des requêtes. La
classe NodeId possède deux attributs :
int num : le numéro
du Node ;
InetSocketAddress addr :
l'adresse TCP/IP
du Node. Lorsqu'un ResourceRequest
est reçu par un Node, il doit utiliser
cette adresse pour se connecter au Node
émetteur.
Le sujet offre les classes d'application déjà écrites :
AppliNode : cette classe démarre
un Node. Elle a deux usages, un pour
le Node racine, et un autre pour tous les
autres Nodes ;
AppliTaskServer : cette classe démarre
le TaskServer ;
Console : cette classe est sa propre classe
d'application.
Le sujet ne vous demande pas de les utiliser directement. Mais ces trois classes sont utilisées en fin de sujet dans les tests d'intégrations déjà écrits.
Il y a 9 questions :
TaskServer ;
Node.
Le barème est donné à titre d'indication.
Vous pouvez faire les questions dans l'ordre de votre choix, avec la contrainte que la dernière intègre toutes les autres et ne peut être testée après les autres testées comme correctes.
Cependant, certaines questions possèdent des thématiques communes :
Node ;
Attention : ce sujet porte sur des échanges réseaux, et le comportement des échanges ne seront corrects que si vous pensez à fermer les connexions quand elles ne servent plus. La plupart du temps, le sujet n'en fera pas mention, et c'est donc à vous d'être vigilant sur cet aspect.
Des tests unitaires sont fournis pour les questions 1—8. Suivez les consignes qui vous sont données pour chacune de ses questions pour les utiliser.
TaskServer
Cette classe, qui est dans le
paquetage tsp.csc4509.tpnote, fournit le code
du serveur de tâches. Lorsqu'un Node obtient
le jeton, il se connecte à ce serveur, lui envoie
un TaskRequest et attend en retour
un TaskResponse. Le serveur TaskRequest
ne gère qu'un seul Node à la fois, et donc
reste en mode synchrone.
Cette classe possède deux attributs :
ServerSocketChannel listenChannel :
le ServerSocketChannel du serveur qui sert à
accepter les clients ;
int resquestNumber : le compteur des tâches
reçues par le serveur. Il sera aussi le résultat à placer dans
le TaskResponse pour notre simulation de tâches.
TaskServer
Le constructeur de TaskServer possède un seul paramètre :
int port : le numéro du port occupé par le
serveur de tâches.
Écrivez le constructeur de TaskServer pour
initialiser totalement l'attribut listenChannel pour
qu'il soit prêt pour réaliser des accept().
Les tests :
Une fois votre méthode écrite, vous pouvez la tester. Pour cela,
retirez l'annotation @Disabled devant la
méthode testTaskServer() de la classe de
test TestTaskServer et lancez ce test.
TaskServer::loop()
Écrivez la méthode TaskServer::loop() qui réalise la
boucle du serveur de tâches. Cette boucle (infinie, sauf en cas
d'exception, que vous ne devez pas gérer) doit :
FullDuplexMsgWorker pour cette
connexion ;
TaskRequest ;
resquestNumber ;
Thread.sleep(1000 *
taskRequest.getTaskDelay()); (en supposant
que taskRequest est la référence sur
le TaskRequest reçu) ;
TaskResponse construit par
l'instruction new
TaskResponse(resquestNumber) ;
Les tests :
Une fois votre méthode écrite, vous pouvez la tester. Pour cela,
retirez l'annotation @Disabled devant la
méthode testLoop() de la classe de
test TestTaskServer et lancez ce test.
Node
La classe Node, qui est dans le
paquetage tsp.csc4509.tpnote, réalise tout
l'algorithme de Naimi-Tréhel. Elle a de nombreux attributs :
NodeId id : l'identifiant
du Node qui contient son numéro ainsi que
son adresse TCP/IP ;
NodeId father et FullDuplexMsgWorker
fatherConnexion : l'identifiant
du Node père et la connexion vers
ce Node. Ces deux attributs sont
à null pour le Node
racine. Ces deux attributs doivent toujours évoluer de pair
(c'est-à-dire, en même temps) ;
NodeId next et FullDuplexMsgWorker
nextConnexion : l'identifiant
du Node suivant dans la liste d'attente,
et la connexion vers ce Node. Ces deux
attributs sont à null si
le Node n'attend pas la ressource ou
s'il est le dernier de la liste d'attente. Ces deux
attributs doivent toujours évoluer de pair
(c'est-à-dire, en même temps) ;
boolean havingToken : booléan à vrai pour
le Node ayant le jeton, et à faux pour tous les
autres ;
boolean requesting : booléan à vrai pour
les Nodes réclamant la ressource et à faux pour
les autres ;
ServerSocketChannel listenChannel : canal
qui sert à accepter toutes les connexions
(des Node fils, du Node précédent,
et de la Console). Ce canal est géré en
asynchrone ;
Selector selector : Selector
gérant les évènements asynchrones du Node ;
Map<SelectionKey, FullDuplexMsgWorker>
inConnexions : dictionnaire gérant toutes les
connexions où une lecture asynchrone peut se produire
(message venant d'un Node fils,
du Node précédent, de
la Console ou
du TaskServer) ;
TaskRequest taskRequest : attribut pour
mémoriser le TaskRequest entre le moment où
le Node le reçoit de
la Console et le moment où il l'envoie
au TaskServer ;
InetSocketAddress serverAddr :
adresse TCP/IP
du TaskServer ;
FullDuplexMsgWorker console : connexion vers
la Console.
Attention : il faut vous
rappelez que father et fatherConnexion
doivent évoluer ensemble. De même, next et
nextConnexion doivent évoluer ensemble.
Si, par exemple,
l'instruction dit father = node i, il faut comprendre
qu'il faut changer father avec le NodeId
du Node i mais aussi
connecter fatherConnexion au Node i.
Les deux constructeurs de la classe sont déjà écrits et ont
correctement initialisé le Node pour le placer
dans l'arbre (soit à la racine, pour le premier constructeur, soit
en fils d'un autre Node pour le second
constructeur). Les
attributs inConnexions, serverAddr
et selector sont
initialisés par ces constructeurs.
La classe fournit aussi deux versions de la
méthode FullDuplexMsgWorker connectTo(), qui ouvre
une connexion TCP synchrone et construit
un FullDuplexMsgWorker pour gérer les échanges. La
première version utilise une adresse TCP/IP
(InetSocketAddress) déjà initialisée, et la seconde
fonctionne avec le
couple (hostName,portNumber). N'hésitez pas les
utiliser pour les connexions qui ne demandent aucune lecture, et
où le mode synchrone ne pose donc pas de problème. Pour
rappel : un émetteur d'un message peut très bien faire
ses envois en mode synchrone, tandis que le récepteur en face gère
les lectures en mode asynchrone.
Il reste 7 méthodes à écrire, qui forment les 7 questions restantes du sujet. Vous pouvez faire les 6 premières dans l'ordre que vous voulez, elles ne dépendent pas les unes des autres. La 7è intégre tout ce qui a été écrit auparavant et ne peut être testée qu'une fois les précédentes terminées et testées. Vous pouvez cependant décider de l'écrire quand vous le voulez.
Node::sendTaskToServer()Cette méthode doit :
Node::serverAddr ;
Node::selector (déjà
initialisé par les constructeurs déjà écrits) ;
FullDuplexMsgWorker pour cette connexion
et l'ajouter à l'attribut
dictionnaire Node::inConnexions (déjà initialisé
par les constructeurs déjà écrits) pour préparer la réception
asynchrone du TaskResponse que va envoyer
le TaskServer ;
TaskRequest au serveur de tâches
(c'est l'attribut Node::taskRequest, qui lors de
l'appel de la méthode Node::sendTaskToServer(), a
déjà été initialisé).
Écrivez la méthode sendTaskToServer().
Les tests :
Une fois votre méthode écrite, vous pouvez la tester. Pour cela,
retirez l'annotation @Disabled devant la
méthode testSendTaskToServer() de la classe de
test TestNode et lancez ce test.
Node::receivingResourceRequest()
Cette méthode réalise les actions d'un Node lorsqu'il
reçoit un ResourceRequest d'un Node
fils. En voici l'algorithme en langage libre :
Pour rappel, resourceRequest.getNodeId() vous donne
l'id du Node émetteur
du ResourceRequest, et
resourceRequest.getNodeId().getAddr() son
adresse TCP/IP. De plus, dans l'arbre, aucun message ne
circule dans le sens père vers fils, donc la connexion vers le
père ne sert qu'à faire des écritures et peut rester synchrone.
Pour rappel,
attention : father
et fatherConnexion doivent évoluer ensemble. De
même, next et
nextConnexion doivent évoluer ensemble. Si, par
exemple, l'instruction dit « father = node
i », il faut comprendre qu'il faut
changer father avec le NodeId
du Node i mais aussi
connecter fatherConnexion au Node
i.
Écrivez la méthode receivingResourceRequest().
Les tests :
Une fois votre méthode écrite, vous pouvez la tester. Pour cela,
retirez l'annotation @Disabled devant les
méthodes testReceivingResourceRequest1(),
testReceivingResourceRequest2() et testReceivingResourceRequest3()
de la classe de
test TestNode et lancez ces tests.
Node::requestingResource()
Cette méthode réalise les actions d'un Node lorsqu'il
reçoit un TaskRequest de sa Console. En
voici l'algorithme en langage libre :
Écrivez la méthode requestingResource().
Les tests :
Une fois votre méthode écrite, vous pouvez la tester. Pour cela,
retirez l'annotation @Disabled devant les
méthodes testRequestingResource1() et
testRequestingResource2()
de la classe de
test TestNode et lancez ces tests.
Node::receivingToken()
Cette méthode réalise les actions d'un Node
lorsqu'il reçoit le Token du Node
précédent dans la liste chaînée. En voici l'algorithme en langage
libre :
Écrivez la méthode receivingToken().
Les tests :
Une fois votre méthode écrite, vous pouvez la tester. Pour cela,
retirez l'annotation @Disabled devant la
méthode testReceivingToken() de la classe de
test TestNode et lancez ce test.
Node::releasingResource()
Cette méthode réalise les actions du Node qui détient
le jeton lorsqu'il libère la ressource. En voici l'algorithme en
langage libre :
Écrivez la méthode releasingResource().
Les tests :
Une fois votre méthode écrite, vous pouvez la tester. Pour cela,
retirez l'annotation @Disabled devant les
méthodes testReleasingResource1() et
testReleasingResource2()
de la classe de
test TestNode et lancez ces tests.
Node::openListenChannel()
Cette méthode réalise l'ouverture du ServerSocketChannel
listenChannel du Node.
Écrivez la méthode openListenChannel() qui initialise
l'attribut listenChannel du Node
pour que ce ServerSocketChannel soit prêt à faire
des accept() en asynchrone sur le
port myPort passé en paramètre. Le nouveau canal
(listenChannel) est enregistré auprès
du Selector du Node
(attribut selector déjà créé et initialisé par les
constructeurs déjà écrits).
Les tests :
Une fois votre méthode écrite, vous pouvez la tester. Pour cela,
retirez l'annotation @Disabled devant la
méthode testOpenListenChannel()
de la classe de
test TestNode et lancez ce test.
Node::algoNaimiTrehel()Cette méthode réalise l'algorithme de Naimi-Tréhel en intégrant dans la boucle d'un serveur asynchrone les méthodes écrites jusqu'ici.
Écrivez la boucle (infinie, sauf en cas d'exceptions que vous n'avez pas à gérer) d'un serveur asynchrone.
Cette boucle doit :
select() du selector
(attribut de Node, déjà créé par les
constructeurs déjà écrits) ;
inConnexions
(attribut de Node, déjà créé et
initialisé par les constructeurs déjà écrits) ;
RESOURCEREQUESTTYPE,
appelez la méthode receivingResourceRequest()
de la question 4 ;
TOKENTYPE, appelez la
méthode receivingToken() de la
question 5 ;
TASKREQUESTTYPE :
console avec
le FullDuplexMsgWorker utilisé pour lire
ce message ;
requestingResource()
de la question 6.
TASKRESPONSETYPE :
releasingResource() de
la question 7 ;
TASKRESPONSETYPE à
la Console.
La boucle doit aussi réaliser toutes les actions que l'on attend
pour une boucle de lectures asynchrones (gestion
des close(), des clear(), etc.)
Les tests :
Pour réaliser les tests d'intégration, nous ajoutons dans le code
du Node une sonde qui va envoyer à un
programme de log de toutes les évolutions de l'état de
chaque Node. Pour cela il faut ajouter dans votre
code, dans la boucle juste avant
l'instruction selector.select() la ligne
suivante :
Ensuite pour passer les tests, lancez depuis la racine du projet (le répertoire où il y a le fichier pom.xml) les scripts suivants :
./TestInteg1.sh
./TestInteg2.sh
./TestInteg3.sh
./TestInteg4.sh
./TestInteg5.sh
./TestInteg6.sh
Les tests de terminent par la ligne Test OK lorsqu'ils réussissent.
Sinon, vous pouvez exploiter le log pour comprendre l'erreur. Pour cela, il faut comprendre fonctionnement de ces tests.
Les tests d'intégration :
Nodes ;Si le log correspond au fichier de référence, le test réussit, sinon le test échoue. Si votre code contient des affichages de Log, ils sont affichés durant tout le déroulement, mais dans tous les cas, le test termine son affichage par un résumé, et son statut (échec, ou réussi). Voici par exemple la fin d'un test qui échoue :
Les fichiers de log à :
La différence à noter entre les deux fichiers est l'absence des
deux dernières lignes dans le fichier du test en échec (à
gauche). Pour information, l'erreur vient du fait que,
dans releasingResource, on a oublié de
mettre requesting à faux.
Une nouvelle ligne de log est générée à chaque changement
d'un Node :
Node. Les Nodes
sans père pointent sur X (cela peut concerner
plusieurs Nodes, car
lorsqu'un ResourceRequest circule, un nouvel
arbre est en construction) ;
Node suivant pour
chaque Node.
Les Nodes sans suivant pointent
sur X ;
Nodes
indiquent l'état de leurs booléens.
T est indiqué pour les Nodes
avec havingToken à vrai, et
R est indiqué pour les Nodes
avec requesting à vrai.
Pour la lecture de ce log :
Node 1, racine, puis
le Node 2, fils de la racine) ;
TaskRequest pour le début du changement de
l'arbre (le Node 2 se détache de
l'arbre) ;
Node
ne le possède) ;
Node 2 possède la ressource et
peut faire sa requête.
Le log s'arrête avec le Node 2, toujours
étiqueté R, alors que toutes les requêtes devraient avoir
été traitées. Il y a donc un bug.
Lorsque le test échoue, il indique aussi le fichier de référence. Vous pouvez le consulter pour voir où le log diffère de cette référence.
Ce TP noté est terminé et vous avez écrit le code permettant de mettre en œuvre l'algorithme réparti de Naimi-Tréhel.
Félicitations !