Ces exercices complètent directement les slides du cours et illustrent plus particulièrement les aspects théorie des langages à travers des exemples classiques.
quelques illustrations d'automates finis (non rédigé!)
hiérarchie de Choisi, grammaire régulière, grammaire context-free, grammaire ambiguë.
analyse shift/reduce, conflits LR, récursivité droite/gauche, automate Bison
(pas d'énoncé, pas de corrigé!)
On se donne en figures jointes quelques illustrations d'automates finis. Il s'agit d'analyser ces automates, de décrire de façon informelle le langage reconnu, éventuellement de déterminer une expression régulière équivalente....
Écrire une grammaire générant le langage représenté par l'expression régulière a*b . Quel est le type de cette grammaire ?
Corrigé :
R1 S → aS R2 S → b
R1 S → Tb R2 T → Ta R3 T → ε
Soit la grammaire G1 :
R1 S → aSa R2 S → aa R3 S → a
L1 engendré par cette grammaire ?L?Corrigé
L1 = {an | n > 0}
L1 est un langage régulier reconnaissable par l'expression régulière a+.R1 S → Sa R2 S → a
Écrire une grammaire générant le langage L = {am bn c p | m,n,p >= 1}.
Si possible utiliser une grammaire linéaire droite ou gauche.
Corrigé
R1 S → aS R2 S → aB R3 B → bB R4 B → bC R5 C → cC R6 C → c
Le langage est régulier, reconnu par l'expression régulière a+b+c+.
La grammaire est ici une grammaire régulière, linéaire à droite.
On peut aussi avoir la forme linéaire gauche suivante :
R1 S → Sc R2 S → Bc R3 B → Bb R4 B → Ab R5 A → Aa R6 A → a
Soit un alphabet A = {a,b,c,d}, écrire une grammaire générant le langage
L = {wdw, w dans {a,b,c}* et w la chaîne miroir de w}
Quel est le type de ce langage et de cette grammaire ?
Corrigé :
R1 S → aSa R2 S → bSb R3 S → cSc R4 S → d
Cette grammaire est context-free, linéaire mais non régulière. La théorie des langages montre que ce langage est algébrique non régulier. Il ne peut donc pas être décrit par une expression régulière ou par un grammaire régulière.
Écrire une grammaire générant le langage L = {an bn | n > 0} .
Quel est le type de ce langage et de cette grammaire ?
Corrigé
R1 S → aSb R2 S → ab
Le langage est algébrique non régulier, la grammaire est context-free, linéaire ni droite ni gauche, et non régulière.
Montrer que la grammaire d'opérateurs suivante est ambiguë.
R1 E → E + E R2 E → E - E R3 E → E * E R4 E → E / E R5 E → ( E ) R6 E → a | b | c
Peut-on faire une grammaire non ambiguë pour le même langage ?
Corrigé
La grammaire est ambiguë si il existe 2 arbres de dérivation possibles pour une même
expression.
par exemple, la chaîne a + b * c correspond à 2 arbres corrects
R1 R3
/ \ / \
R6 R3 R1 R6
| / \ / \ |
a R6 R6 R6 R6 c
| | | |
b c a b
On peut trouver une grammaire non ambiguë pour le même langage, en rajoutant des symboles non-terminaux.
"Une Expression est une somme de Termes qui sont des produits de Facteur".
E → E + T | E - T | T T → T * F | T / F | F F → ( E ) | a | b | c
Le langage L = {an bn cn| n > 0} est non algébrique (ou dépendant du contexte, ou context-sensitive), c'est-à-dire qu'il n'existe pas de grammaire context-free permettant de générer ce langage.
Ce langage est engendré par la grammaire suivante :
R1 S → aBSc R2 S → aBc R3 Ba → aB R4 Bc → bc R5 Bb → bb
Donner les pas de dérivation nécessaires pour reconnaître les chaînes "abc", puis "aabbcc", puis "aaabbbccc".
Corrigé
Considérons les deux langages :
L1 = {an bn cp | n,p > 0} L2 = {an bp cp | n,p > 0}Quelle est la nature des langages : L1 , L2 , L1 ∩ L2 et L1 ∪ L2 ?
Corrigé:
L1 et L2 sont algébriques.
Les 2 langages sont aussi non ambigus et déterministes.
an bn
L1 ∩ L2 == {an bn cn| n > 0} n'est pas algébrique (cf. exercice 2.7).
L1 ∪ L2 est algébrique.
L1 ∪ L2 est un langage algébrique inhéremment ambigu, c'est-à-dire qu'il ne peut être reconnu que par des grammaires algébriques ambiguës et donc non déterministes. (preuve par lemme d'Ogden)
Les langages suivants sont-ils algébriques ou pas ?
L1 = {an bp cn dp| p,n > 0}
L2 = {an bn cp dp| p,n > 0}
L3 = {an bp cp dn| p,n > 0}
Suggestion : On peut aussi analyser la question en terme d'automates à pile plutôt que de grammaire context-free.
Corrigé:
L2 et L3 sont algébriques, et facilement reconnaissables avec une Pile.
L1 n'est pas algébrique (...lemme d'Ogden...).
Conséquence pratique : Vérifier l'égalité du nombre d'arguments entre la déclaration d'une fonction et son utilisation ne peut pas être fait de façon systématique par l'utilisation de grammaires context-free.
Écrire les décalages/réductions nécessaires pour reconnaître le
fragment ababa avec la grammaire suivante :
R1 S → AB R2 A → ab R3 B → aba
Corrigé :
| pas | chaîne d'entrée | liste | action |
| 0 | •ababa | Décalage | |
| 1 | a•baba | a | Décalage |
| 2 | ab•aba | ab | Reduc : R2 |
| 3 | ab•aba | A | Décalage |
| 4 | aba•ba | Aa | Décalage |
| 5 | abab•a | Aab | Décalage |
| 6 | ababa• | Aaba | Reduc : R3 |
| 7 | ababa• | AB | Reduc : R1 |
| 8 | ababa• | S | succès |
Écrire les décalages/réductions nécessaires pour reconnaître le
fragment aaaa avec la grammaire récursive gauche :
R1 S → Sa R2 S → a
Corrigé
| pas | chaîne d'entrée | liste | action |
| 0 | •aaaa | Décalage | |
| 1 | a•aaa | a | Reduc : R2 |
| 3 | a•aaa | S | Décalage |
| 4 | aa•aa | Sa | Reduc : R1 |
| 5 | aa•aa | S | Décalage |
| 6 | aaa•a | Sa | Reduc : R1 |
| 7 | aaa•a | S | Décalage |
| 8 | aaaa• | S | succès |
Écrire les décalages/réductions nécessaires pour reconnaître le
fragment aaaa avec la grammaire récursive droite :
R1 S → aS R2 S → a
Corrigé :
| pas | chaîne d'entrée | liste | action |
| 0 | •aaaa | Décalage | |
| 1 | a•aaa | a | Décalage |
| 2 | aa•aa | aa | Décalage |
| 3 | aaa•a | aaa | Décalage |
| 4 | aaaa• | aaaa | Reduc : R2 |
| 5 | aaaa• | aaaS | Reduc : R1 |
| 6 | aaaa• | aaS | Reduc : R1 |
| 7 | aaaa• | aS | Reduc : R1 |
| 8 | aaaa• | S | succès |
Laquelle choisiriez-vous? Laquelle pour une analyse ascendante comme bison, ou pour une analyse descendante comme javacc
Corrigé :
Analyse descendante (LL): Récursivité droite obligatoire
Analyse ascendante (LR) : Récursivité gauche plus efficace
Une application directe de l'exercice précédent est le schéma d'analyse syntaxique "ligne à ligne" souvent utilisé pour les exercices de travaux pratiques
Soit une spécification Bison de la forme :
%%
Liste_Lignes : /* mot vide */ /* Règle 1 */ {Action1;}
| Liste_Lignes PhraseCorrecte '\n' /* Règle 2 */ {Action2;}
PhraseCorrecte : .......
%%
Écrire les décalages/réductions nécessaires pour l'analyse LR d'un fichier contenant 0,1,2,... lignes avec une "PhraseCorrecte" par ligne.
Préciser quand sont exécutées les Actions 1 et 2.
Corrigé
On notera (cf. exercice suivant) que Bison rajoute de façon conventionnelle un "axiome" englobant sous la forme d'une règle 0 "$accept : Axiome_de_la_spec $end", où "$end" désigne le Token EOF (==0) et "$accept" identifie une terminaison correcte de l'analyse.
a) Fichier vide :
| pas | Pile d'analyse | action |
| 0 | •EOF | Réduction Règle1 et Action1 |
| 1 | Liste_Lignes • EOF | Décalage |
| 2 | Liste_Lignes EOF • | Accept. (Réduction Règle0) |
b) Fichier monoligne :
| pas | Pile d'analyse | action |
| 0 | • PhraseCorrecte \n EOF | Réduction Règle1 et Action1 |
| 1 | Liste_Lignes • PhraseCorrecte \n EOF | "Meta-Décalage" |
| 2 | Liste_Lignes PhraseCorrecte • \n EOF | Décalage |
| 3 | Liste_Lignes PhraseCorrecte \n • EOF | Réduction Règle2 et Action2 |
| 4 | Liste_Lignes • EOF | Décalage |
| 5 | Liste_Lignes EOF • | Accept (Réduction Règle0) |
c) Fichier multiligne :
Par récurrence, on voit que pour un fichier avec N lignes "• (PhraseCorrecte \n){N} EOF", il suffit de boucler N fois sur les étapes 1,2 et 3 de l'analyse précédente.
L'Action1 est donc toujours exécutée une seule fois en début de fichier. L'Action2 est exécutée après chaque fin de ligne et dans l'ordre des lignes (merci à la récursivité gauche !).
On notera que l'absence de "\n" juste avant la fin de fichier est une erreur de syntaxe. Ceci explique un warning courant "missing newline before EOF" dans beaucoup d'usage informatique.
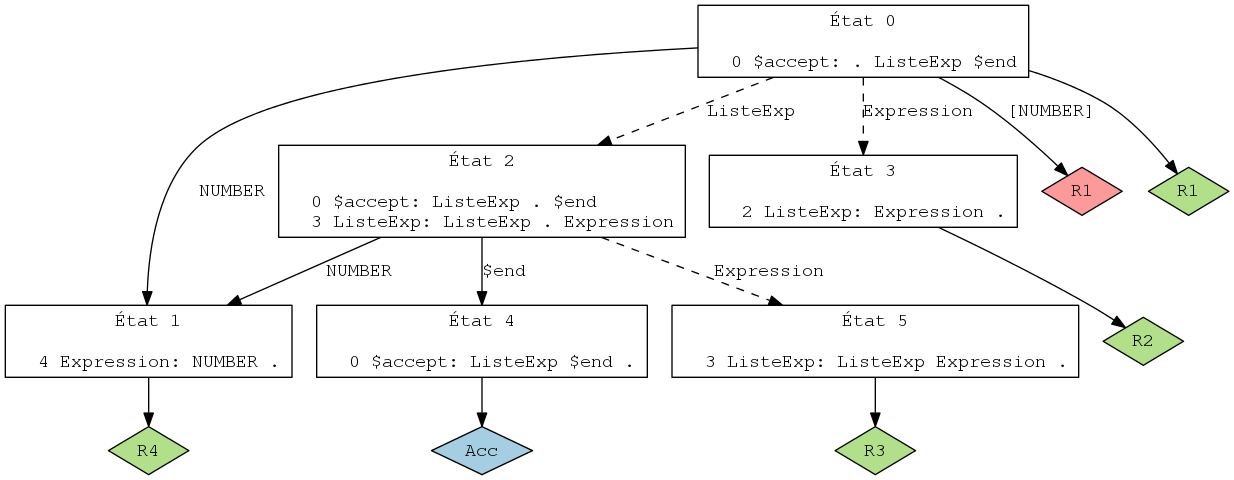
La grammaire suivante est ambiguë et engendre un conflit de type
décalage/réduction.
ListeExp:
| Expression
| ListeExp Expression
;
Expression: NUMBER
;
On se donne les fichiers conflit0.flex, conflit0.bison et conflit.data.
Bison peut aider à diagnostiquer les conflits et fournit l'accès à l'automate de résolution LR. Pour cela, utiliser l'option "--report=state" ou "-v" :
bison --report=state conflit0.bison more conflit0.output
Essayer d'analyser l'automate LR décrit dans le fichier "conflit0.output". (cf. mementoBison)
Suivant les versions de bison, et avec quelques outils complémentaires, il est aussi possible d'obtenir une visualisation graphique
de l'automate par exemple sous la forme : SVG pour conflit0.output ou PNG pour conflit0.output
Corrigé
Il a été vu en cours que la grammaire suivante est ambiguë :
Instruction : If Instruction
;
IfInstruction : IF Expr Instruction
| IF Expr Instruction ELSE Instruction
;
Expr : ...
Le type de conflit induit par cette grammaire est-il de type décalage/réduction ou réduction/réduction? Comment est-il résolu par l'analyseur généré par Bison?
Corrigé :
Ce problème est connu sous le nom du dangling
else. L'élimination de l'ambiguïté est ici possible en écrivant la grammaire sous la forme :
Ifinstr : instr_close
| instr_non_close
;
instr_close : IF expr instr_close ELSE instr_close
| autre
;
instr_non_close : IF expr instr
| IF expr instr_close ELSE instr_non_close
Trois exemples :
E → E + T | T | id | ... T → id | number
/* expressions caml */ Exp → number | id | Exp - Exp | - Exp | Exp Exp |...
/* conflit issu du lookahead limité */ S → H1 b c x | H2 b c y H1 → a | ... H2 → a | ...
N.B. : Le plus souvent les conflits reduce/reduce sont des erreurs de conception de la grammaire avec des redondances de définitions.
{kind=link}
{kind=link}