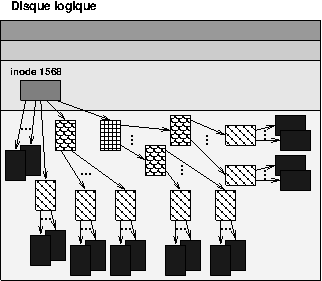
L’idée de base pour l’organisation des adresses (directes et indirectes) est de ne pas limiter en taille le fichier (grâce aux adresses indirectes) tout en ne pénalisant pas l’accès aux petits fichiers (grâce aux adresses directes). Ainsi, la taille maximale d’un fichier est supérieure à la taille d’une partition et très nettement supérieure à la taille raisonnable d’un fichier. L’organisation des adresses de blocs de données dans l’inode date de la version 2 du système de fichier Ext (Extended FS) de GNU/Linux. Ext3 ajoute la journalisation des opérations d’écriture sur le disque tant qu’elles ne sont pas terminées afin de garantir l’intégrité des données en cas de panne du système. Ext4 permet de créer des fichiers de taille supérieure grâce à l’extension de la description d’un inode.
Premières commandes sur les fichiers ordinaires. Les premières commandes de cette page sont des commandes du type filtre. Un filtre est un programme qui réalise un traitement sur un flot de données, ici produit par la lecture d’un fichier texte en entrée, pour fournir un flot de données en sortie. Ce concept plutôt classique prend tout son intérêt grâce aux différentes formes que peuvent revêtir les flots de données. Ce point sera détaillé dans la section sur le shell avec les redirections et les tubes. Les filtres présentés maintenant sont des filtres dits « simples ». Ces commandes acceptent de très nombreuses options que nous n’avons pas le temps ni l’espace de décrire ici. Avant d’appliquer un filtre sur un fichier, il est préférable de s’assurer que le fichier contient du texte. La commande file permet de le savoir. Dans le cas de texte, elle précise si les caractères sont uniquement des caractères ASCII ou s’ils contiennent d’autres caractères, par exemple des caractères accentués ISO-8859-X (X dans [1–15]).
La commande de base pour afficher le contenu d’un fichier de texte est cat suivie du nom du fichier. Cette commande accepte plusieurs noms de fichiers comme arguments, ce qui permet de les concaténer (cat signifie concatenate) en un seul flot de sortie.
La commande cat n’est guère pratique avec des fichiers dont la taille dépasse celle de l’écran car l’affichage défile de façon ininterrompue et seules les dernières lignes affichées restent visibles sur l’écran à la fin de la commande. La commande more prend en compte le nombre de lignes de l’écran pour offrir un affichage page par page. Cette commande affiche une page du fichier suivie d’une ligne d’information avec le pourcentage de texte déjà affiché et elle attend une requête du clavier. Si la commande est appelée avec plusieurs arguments, elle affiche en plus un en-tête avec le nom du fichier entre deux lignes constituées de caractères deux points (« : »). Les requêtes les plus utilisées sont espace (ou z) pour afficher la page suivante, ENTRÉE pour afficher la ligne suivante, b pour afficher la page précédente et q (ou Q) pour quitter la commande avant la fin.
La commande tail affiche la fin du fichier passé en argument. Par défaut, tail affiche les dix dernières lignes. Cette commande permet également de suivre dynamiquement l’évolution d’un fichier. En utilisant l’option −f (fil de l’eau), elle affiche la fin du fichier puis elle entre dans une boucle infinie avec affichage chaque seconde de toute nouvelle information qui est ajoutée au fichier.
La commande head affiche le début du fichier passé en argument. Par défaut, head affiche les dix premières lignes. Cette commande ressemble à la commande tail mais elle est plus limitée au niveau des options. Par contre, elle peut accepter plusieurs fichiers comme arguments. Dans ce cas, la commande head affiche avant le début de chaque fichier, un en-tête avec le nom du fichier.
Toujours pour un fichier de texte, la commande wc (word count) permet de compter les lignes, les
mots et les caractères. Lorsque la commande est appelée avec plusieurs arguments, elle affiche également
un total cumulé.
Retour à la page de cours