Architecture
Evolution of processors performance
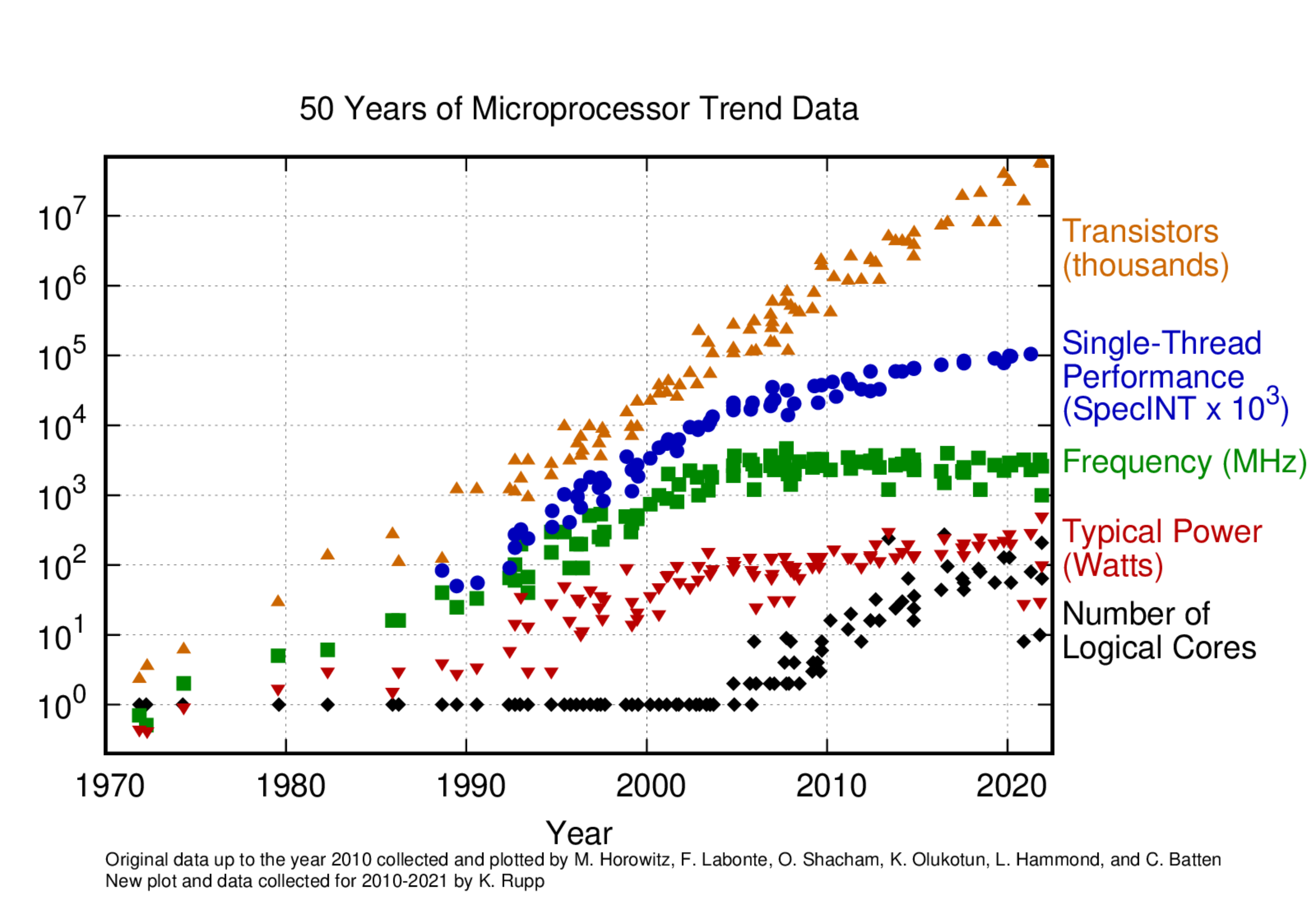
Source: https://github.com/karlrupp/microprocessor-trend-data
Sequential processor
- An instruction requires N steps
- Fetch: load instruction from memory
- Decode: identify the instruction
- Execute: execution of the instruction
- Writeback: storage of the result
- Each step is processed by a processor circuit
- Most circuits are not used at every stage → One instruction is executed every N cycles

Instruction pipeline
At each stage, several circuits are used
→ One instruction is executed at each cycle

Micro architecture of a pipeline
- Each stage of the pipeline is implemented by a set of logic gates
- Execute step: one subcircuit per type of operation (functional unit)
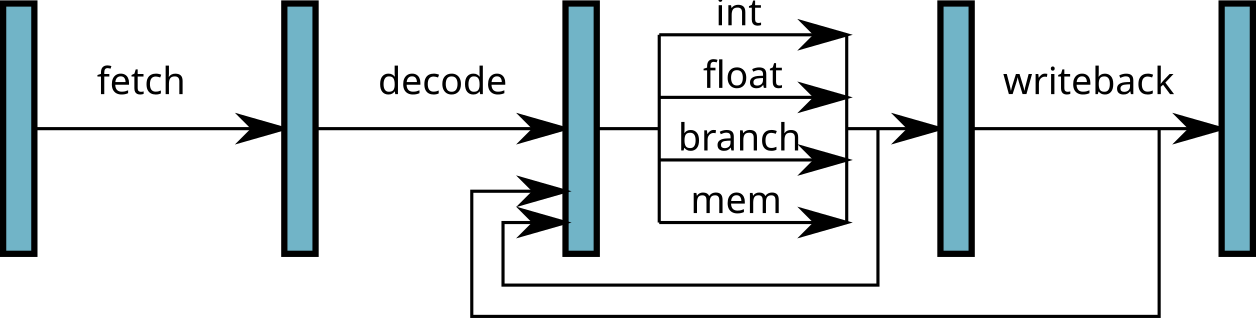
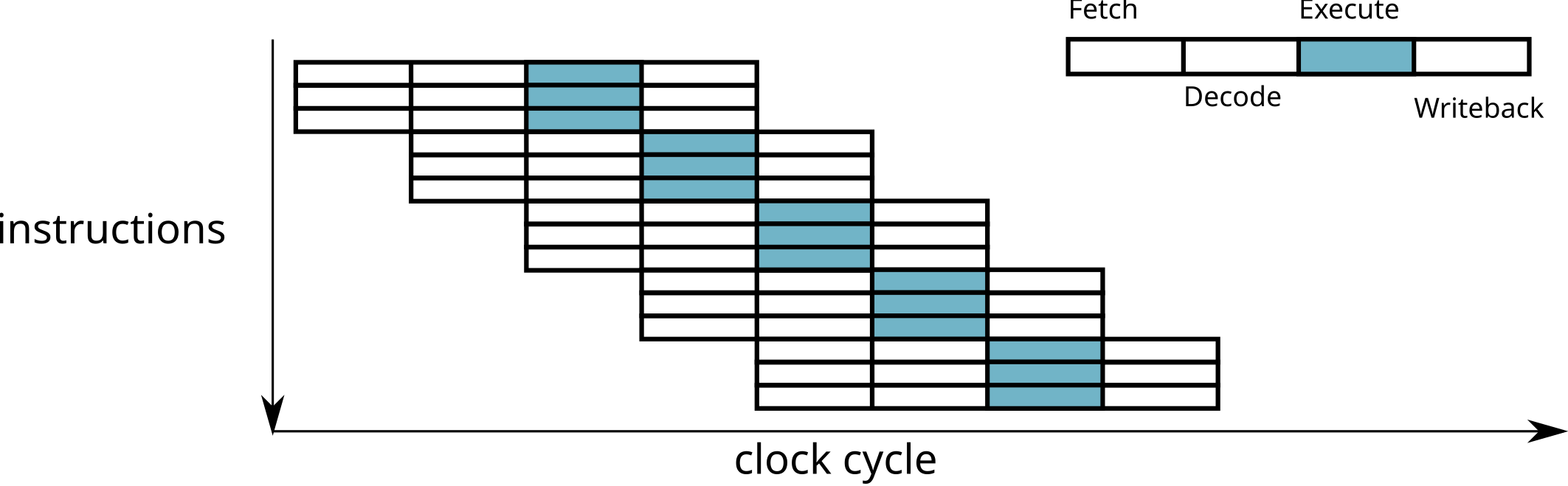
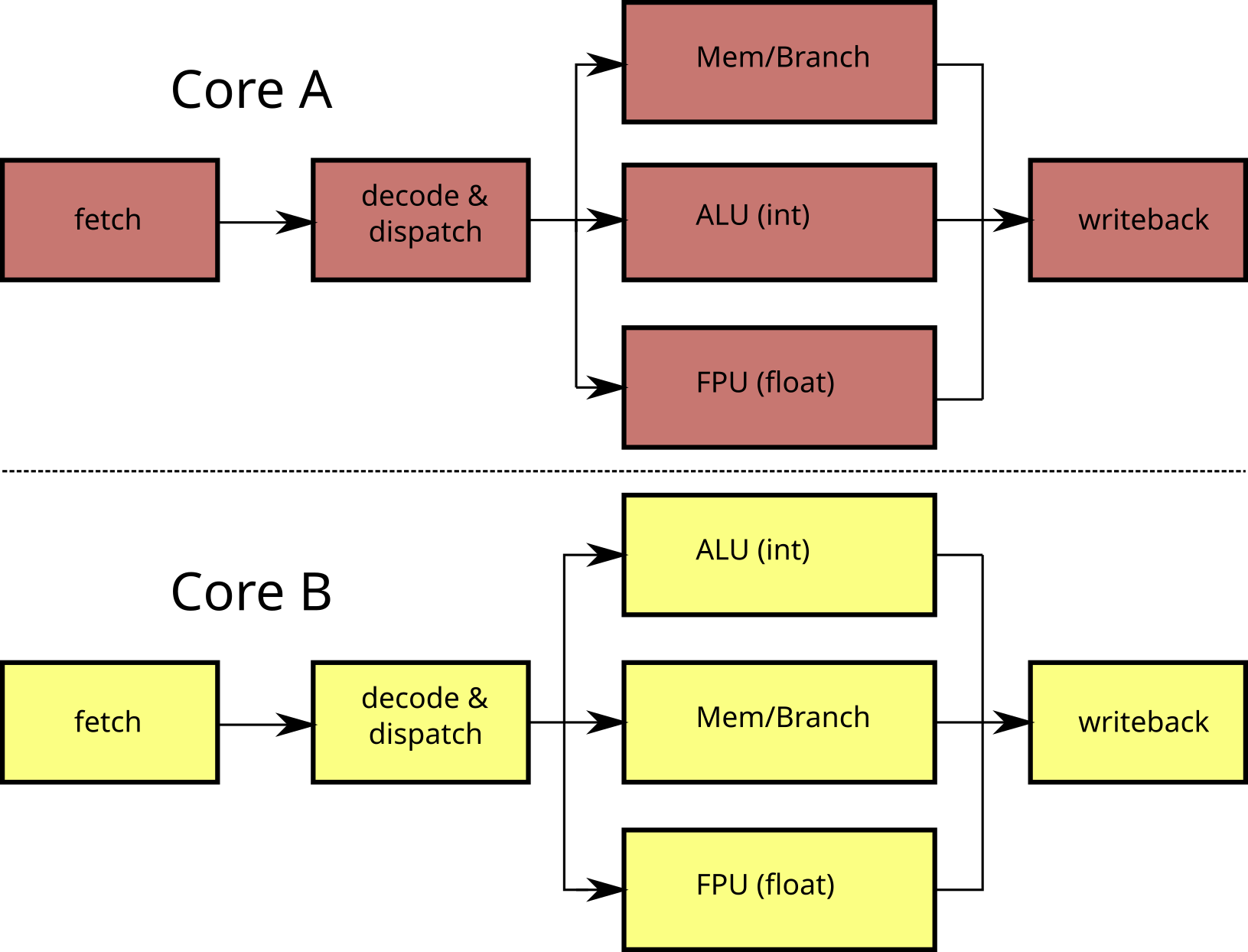
Superscalar processors
- Use of different functional units simultaneously
⟹ several instructions executed simultaneously!
- Require to load and decode several instructions simultaneously
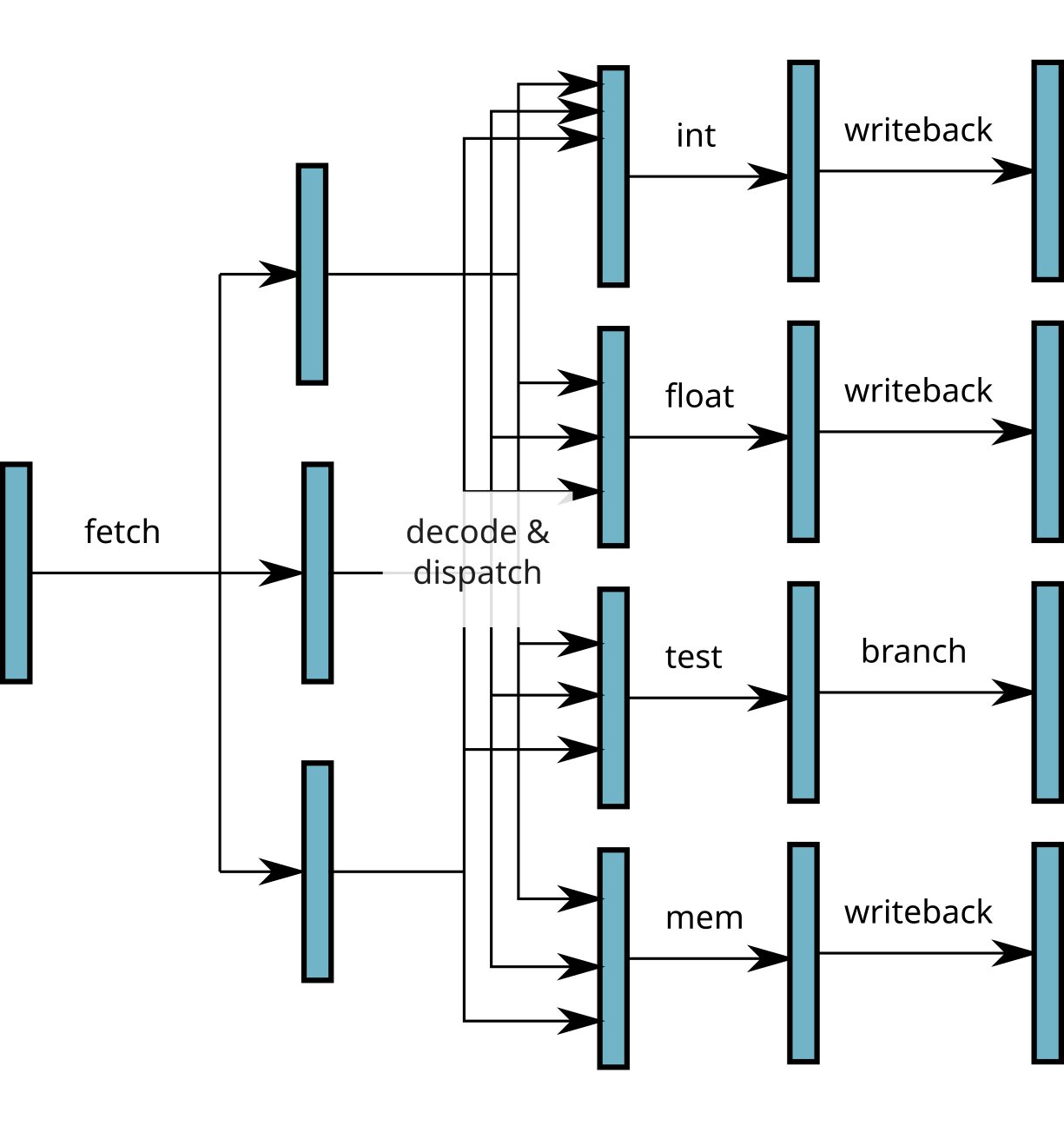
Superscalar processors throughput
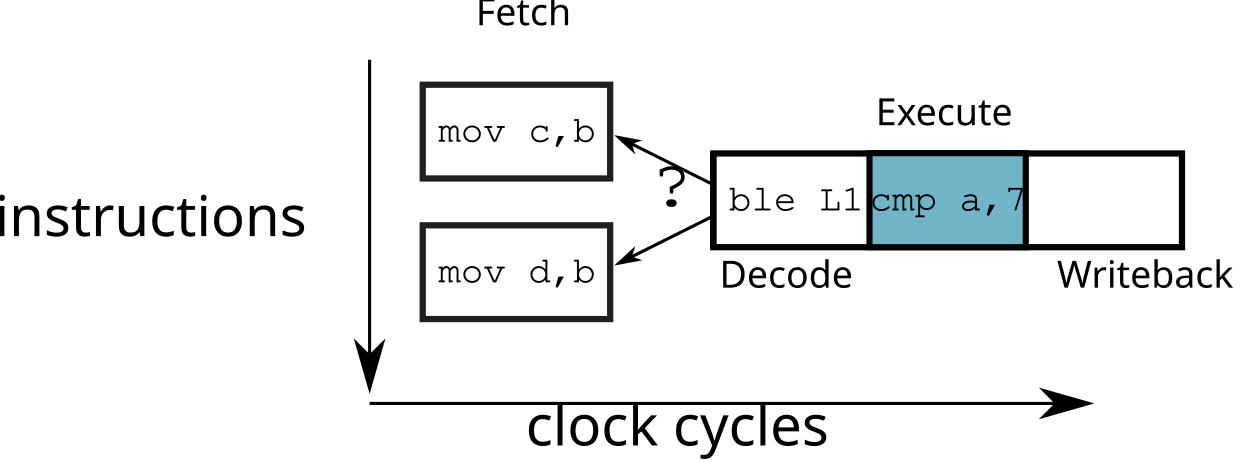
Branching
- How to fill the pipeline when the instructions contain conditional jumps?
cmp a, 7 ; a > 7 ?
ble L1
mov c, b ; b = c
br L2
L1: mov d, b ; b = d
L2: ...- In case of a bad choice: the pipeline must be “emptied”
⟹ waste of time
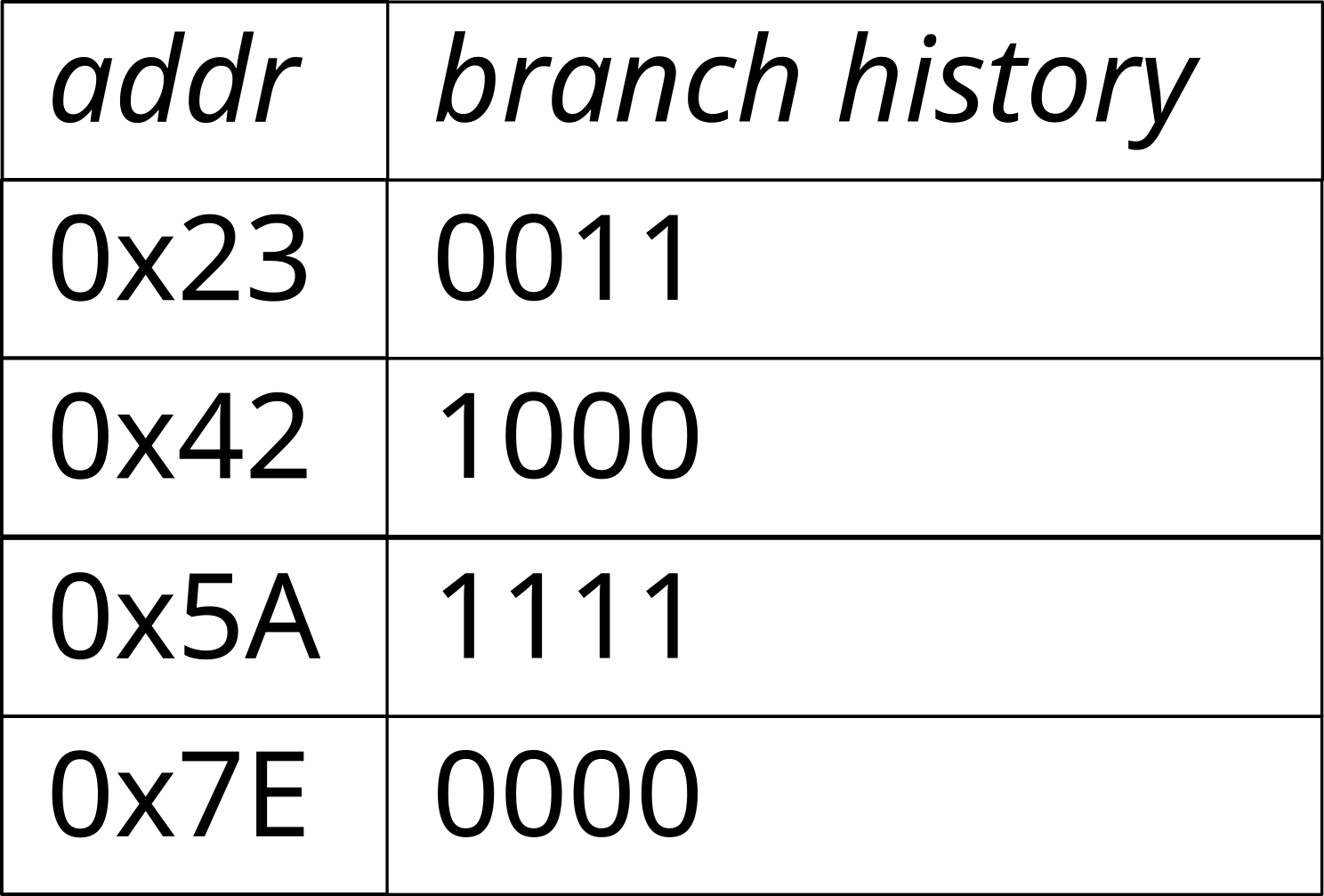
Branch prediction
- The processor implements a prediction algorithm
- General idea:
- For each conditional jump, store the previous results
0x12 loop:
...
0x50 inc eax
0x54 cmpl eax, 10000
0x5A jl loop
0x5C end_loop:
...
Hyperthreading / SMT
Problem with superscalar / vector processors:
- The application must have enough parallelism to exploit
- Other applications may be waiting for the CPU
Simultaneous Multi-Threading (SMT, or Hyperthreading)
- Modify a superscalar processor to run multiple threads
- Duplicate some circuits
- Share certain circuits (eg FPU) between processing units
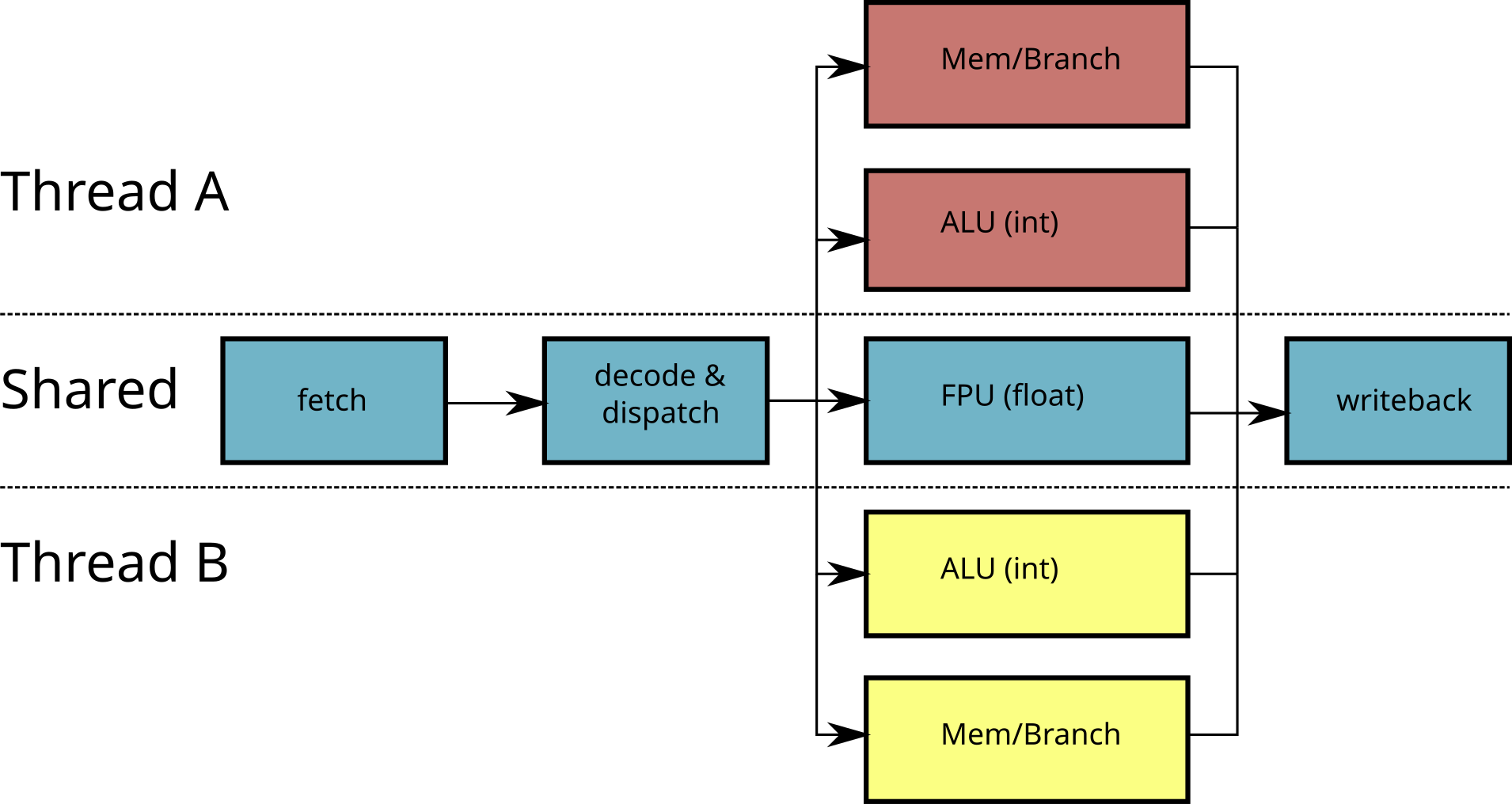
Multi-core processors
Limited scalability of SMT
dispatcher is shared
FPU is shared
→ Duplicate all the circuits
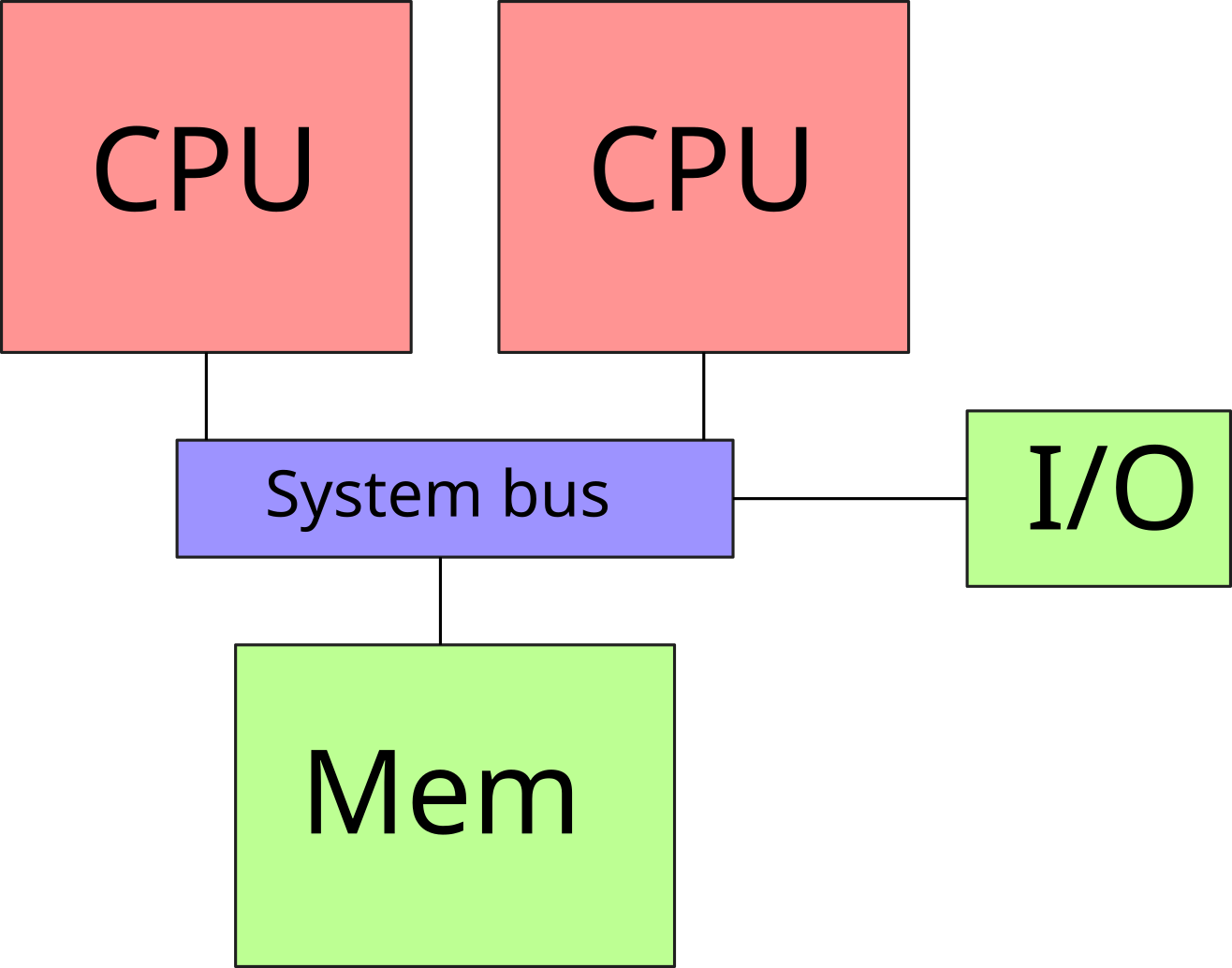
Symmetric Multi-Processing (SMP)
- Multiple processors sockets on a motherboard
- The processors share the system bus
- Processors share memory
- Scalability problem: contention when accessing the bus
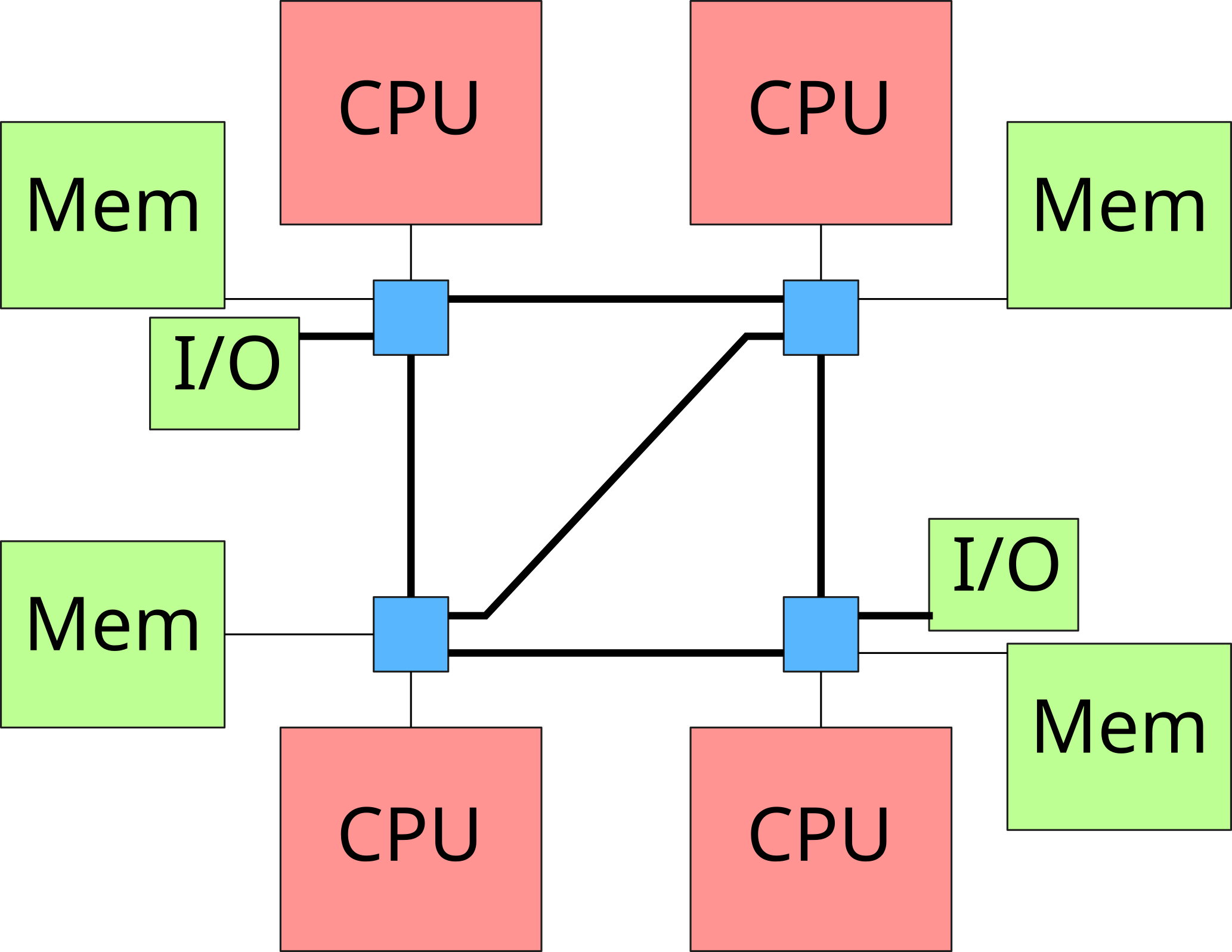
NUMA architectures
- NUMA nodes connected by a fast network
- Memory consistency between processors
- Privileged access to the local
- Access possible (with an additional cost) to memory banks located on other nodes
→ Non-Uniform Memory Architecture
Memory wall
- Until 2005: increase in CPU performance: 55 % / year
- Since 2005: increase in the number of cores per processor
- Increased memory performance: 10 % / year
- The memory accesses which are now expensive: Memory Wall
- Mechanisms are needed to improve memory performance

Cache memory
- Memory access (RAM) are very expensive (approx. 60 ns - approx. 180 cycles)
- To speed up memory access, let’s use a fast cache memory:
- L1 cache: very small capacity (typically: 64 KiB), very fast (approx. 4 cycles)
- L2 cache: small capacity (typical: 256 KiB), fast (approx. 10 cycles)
- L3 cache: large capacity (typically: between 4 MiB and 30 MiB), slow (approx. 40 cycles)
- Very expensive hard disk access (SWAP): approx. 40 ms (150 μs on an SSD disk)

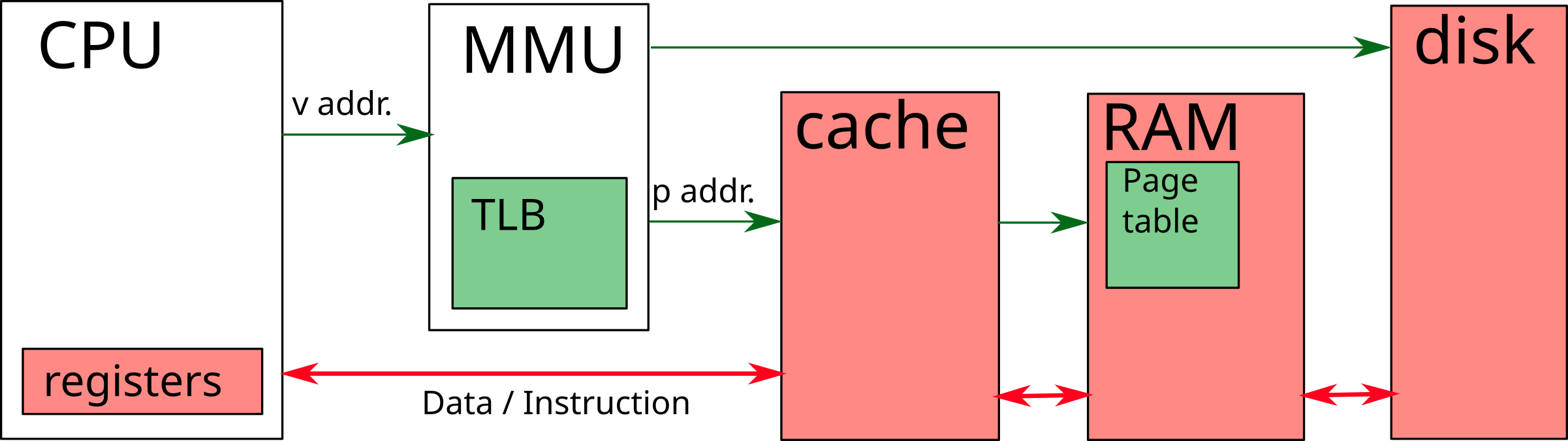
Memory Management Unit (MMU)
- Translates virtual memory addresses into physical addresses
- Look in the TLB (Translation Lookaside Buffer), then in the page table
- Once the physical address is found, request the data from the cache / memory
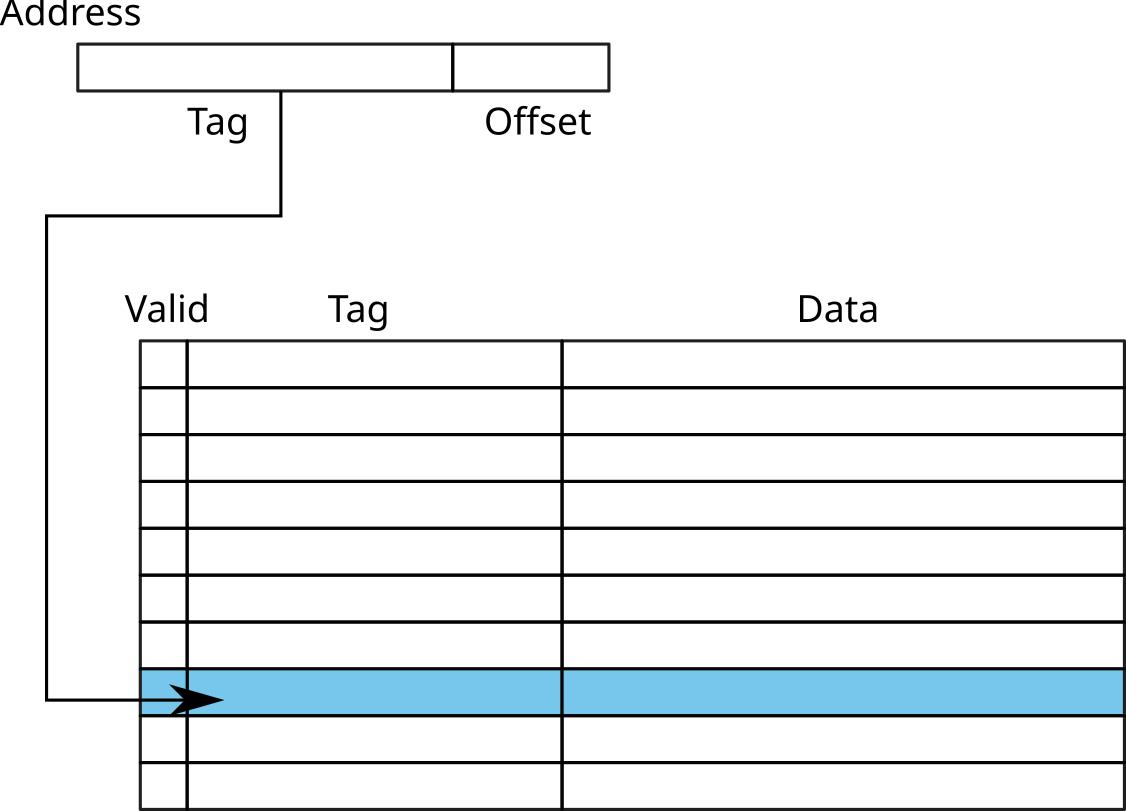
Fully-associative caches
- Cache = array with N entries
- For each reference, search for Tag in the array
- If found (cache hit) and Valid = 1: access to the cache line Data
- Otherwise (cache miss): RAM access
- Problem: need to browse the whole table
→ Mainly used for small caches (ex: TLB)
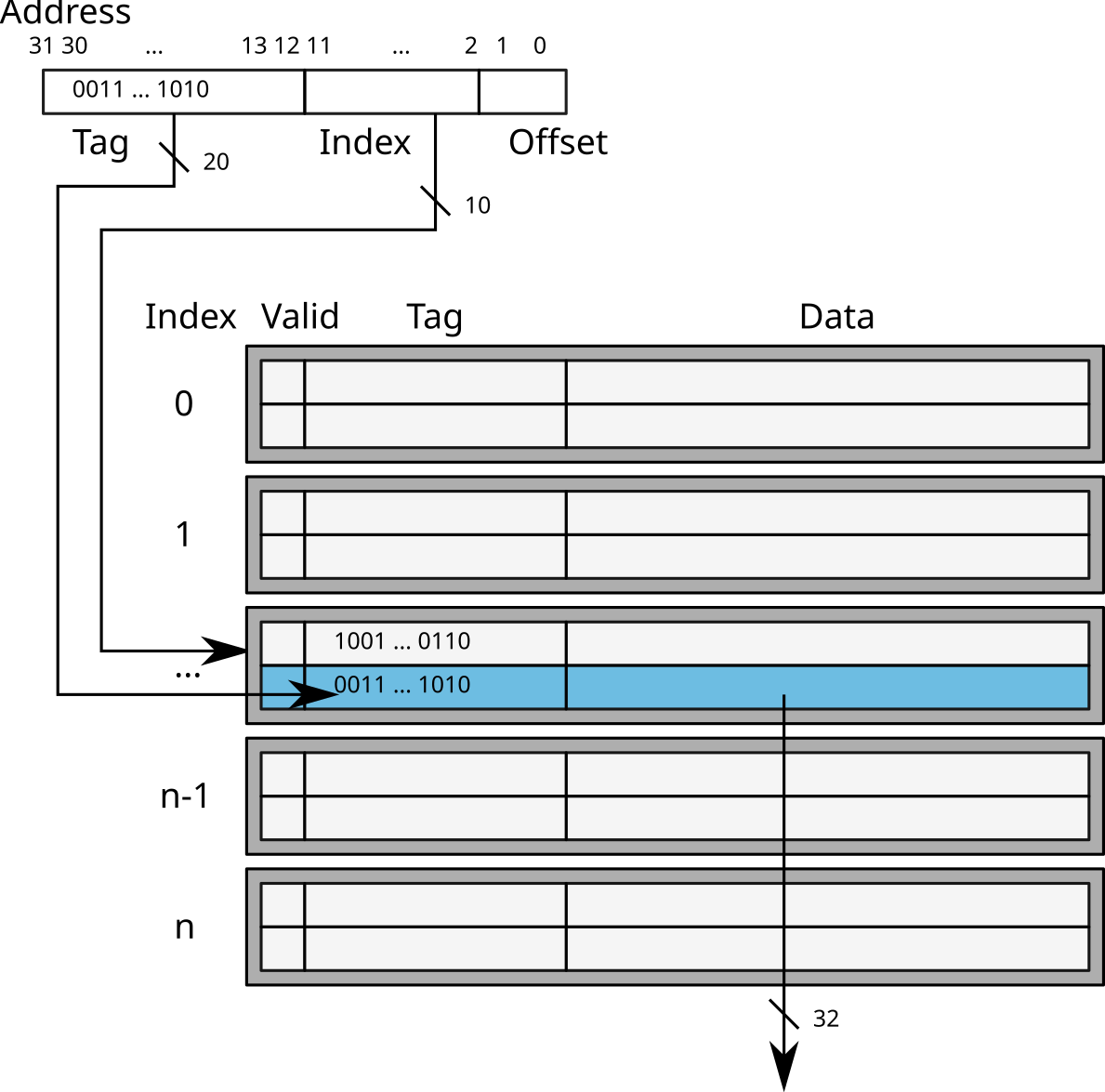
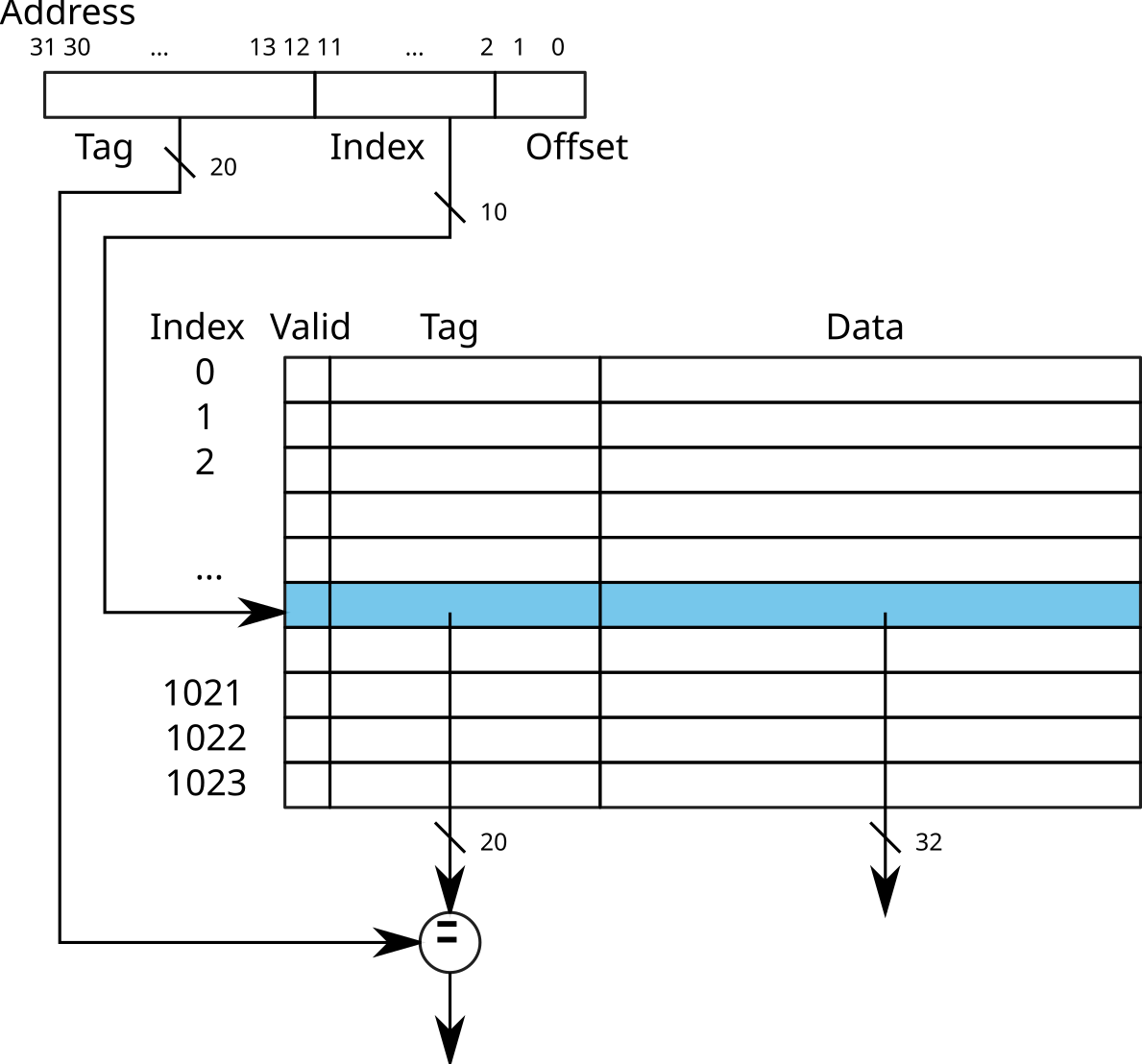
Direct-mapped caches
- Using the least significant bits of the address to find the index of the entry in the cache
- Comparison of the Tag (most significant bits) of the address and the entry.
→ Direct access to the cache line
Warning: risk of collision
example:
0x12345678and0xbff72678
Set-associative caches
- Index to access a set of K cache lines
- Search for the Tag among the addresses of the set
→ K-way associative cache (in French: Cache associatif K-voies)