Gestion de la mémoire
Exercice 1 : L'écroulement (thrashing)
Préparation
Se placer dans un répertoire de travailtar xvfz ecroul_4Go.tgz
cd Ecroul_4Go
Question 1
cache_line.c et alea.c initialisent un tableau de N méga octets. Comparer leur manière de travailler.---beginCorr
cache_line.c accède aux éléments du tableau dans l'ordre, page par page.
alea.c accède aux éléments du tableau de manière aléatoire.
---endCorr
Question 2
Lancer les programmescache_line et alea et
comparer leurs performances. Par défaut ces programmes utilisent
des tableaux de 3 Mo.---beginCorr
$ ./cache_line
[...]
10000000 iterations in 0.092259 s (0.009226 µs per iteration)
$
$ ./alea
[...]
10000 iterations in 0.001142 s (0.114200 µs per iteration)
$
---endCorr
Question 3
Déterminer à l'aide de la commande 'free -m', la quantité de mémoire physique disponible et la taille de l'espace disque disponible pour le swap (variable selon le type de PC utilisé).---beginCorr
Sur la machine b04-01 :
total used free shared buffers cached Mem: 3974 529 3444 0 29 393
-/+ buffers/cache: 106 3867
Swap: 6015 92 5923
i.e. 3444 Mo de mémoire physique disponible et 5923 Mo de swap (92 utilisé).
---endCorr
Question 4
La commande vmstat permet de voir l'évolution des processus et du système dans le temps. Elle affiche à l'intervalle de temps choisi divers paramètres utiles pour cet exercice :- r : nombre de processus "runnable" (vmstat lui-même n'est pas compté)
- b: nombre de processus bloqués en attente disque
- fre: mémoire libre disponible (en Ko)
- si: "swap in" lecture de pages sur le disque (en Ko/s)
- so: "swap out" écriture de pages sur le disque (en Ko/s)
- id: "idle" pourcentage de temps pendant lequel la CPU est inutilisée
Dans une fenêtre 1, exécuter la commande vmstat 1 (le 1 signifie 1 affichage par seconde)
Dans une fenêtre 2:
Où
n correspond à partieEntiere(0.25 x
quantité de mémoire physique
libre)Commenter l'évolution des champs r, b, free, si, so, id (dans la fenêtre 1) et les différences de temps d'exécution entre les différents processus.
Au vu de la valeur de n, à combien de défauts de pages mineurs pouvait-on s'attendre ?
---beginCorr
Sur b04-01 et n = 1000, on obtient :
$ /usr/bin/time ./alea 1000
Allocating 256000 * 4096 bytes
Binding current thread to core #0
START !
STOP !
10000 iterations in 0.002074 s (0.207400 µs per iteration)
0.04user 0.66system 0:00.76elapsed 92%CPU (0avgtext+0avgdata
1027508maxresident)k
0inputs+0outputs (0major+256901minor)pagefaults 0swaps
Par ailleurs, comme chaque page fait 4 ko, notre application utilise n*1024 Ko, soit n*1024/4 = 256000 pages. On retrouve à peu près le nombre de défauts de pages mineur affiché par time.
---endCorr
Question 4
Dans la fenêtre 1, exécuter la commande./use_memory
n (avec n=partieEntiere(0.5 x quantité de mémoire
physique
libre)Dans la fenêtre 2, lancer la commande
./alea m
(avec m=partieEntiere(0.25 x quantité de mémoire physique
libre)Même manip avec m=partieEntiere(0,5 x quantité de mémoire physique totale).
---beginCorr
(avec ./use_memory 2000):
$ ./alea 1000
Allocating 256000 * 4096 bytes
Binding current thread to core #0
START !
STOP !
10000 iterations in 0.004426 s (0.442600 µs per iteration)
$ ./alea 2000
Allocating 512000 * 4096 bytes
Binding current thread to core #0
START !
STOP !
10000 iterations in 31.411524 s (3141.152400 µs per
iteration)
Avec 2000 Mo, on commence à utiliser le swap ==> Les perf chutent (on voit notamment des entrées/sorties avec vmstat).
---endCorr
Exercice 2 : Remplacement de pages
Préparation
Se placer dans un répertoire de travailtar xvfz remplacementDePages.tgz
cd RemplacementDePages
Question 1
Un processus référence successivement les pages 0, 1, 2, 0, 1, 0, 2, 0. Il dispose d'une mémoire avec 2 cadres de page initialement vides.
Indiquer, dans le fichier anomalieDeBelady.txt, les séquences de défauts de page générés par ce processus, pour chacun des trois algorithmes de remplacement de pages : FIFO, LRU, et Optimal.---beginCorr
remplacementDePages.corrige.txt
---endCorr
Exercice 3 : De l'alignement des structures
Préparation
Se placer dans un répertoire de travailtar xvfz align.tgz
cd Align
make
Le module useGetrusage.c facilite l'utilisation de la fonction getrusage. Etudier le "man getrusage" pour bien comprendre le rôle de cette fonction. Puis analyser useGetrusage.c pour comprendre son fonctionnement.
Question 1
Comparer la structure tableElement des différents fichiers align.c, nonAlign.c, nonAlignPacked.cAvec diff, comparer nonAlign.c et nonAlignPacked.c
---beginCorr
Dans align.c, tableElement contient 1 int, puis 2 short.
Dans nonAlign.c et nonAlignPacked.c, tableElement contient 1 short, puis 1 int, puis 1 short.
nonAlign.c et nonAlignPacked.c ne diffèrent que par la présence d'une instruction " __attribute__((packed))" dans le typedef
---endCorr
Question 2
Exécuter align, nonAlign et nonAlignPackedInterpréter les résultats
---beginCorr
$ alignTaille d'un element de t = 8Offset
t[0].unInt
= 0 (sizeof = 4)Offset t[0].unShort
= 4
(sizeof = 2)Offset t[0].unShort2
= 6 (sizeof
= 2)ru_utime
= 0.628906 sru_stime
= 1.769531 sru_utime+ru_stime
=
2.398437 sru_minflt
= 97655ru_majflt
=
0ru_nswap
=
0
########################$ nonAlignTaille d'un element de t =
12Offset t[0].unShort
= 0
(sizeof = 2)Offset
t[0].unInt
= 4 (sizeof = 4)Offset t[0].unShort2
= 8 (sizeof
= 2)ru_utime
= 0.787109 sru_stime
= 2.712890 sru_utime+ru_stime
=
3.499999 sru_minflt =
146483ru_majflt
=
2ru_nswap
=
0
########################$ nonAlignPackedTaille d'un element de t = 8Offset t[0].unShort
= 0
(sizeof = 2)Offset
t[0].unInt
= 2 (sizeof = 4)Offset t[0].unShort2
= 6 (sizeof
= 2)ru_utime
= 0.642578 sru_stime
= 1.757812 sru_utime+ru_stime
=
2.400390 sru_minflt
= 97655ru_majflt
=
0ru_nswap
=
0Dans nonAlign, tableElement a une taille de 12 octets alors qu'elle est de 8 pour les autres. Ceci est dû au fait que le compilateur cherche, par défaut, à avoir des feuilles de structure sur des frontières d'octets (cf. question 3). Comme tableElement est plus gros, le processus est plus gros et donc prend plus de temps à l'exécution (car il faut swapper hors de la mémoire des processus courants (ex. fenêtre X, etc.).
Dans nonAlignPacked, tableElement a une taille de 8 octets car, avec l'instruction "__attribute__((packed))", on a forcé le compilateur à quitter son comportement par défaut et donc compresser la structure.
align et nonAlignPacked ont un temps d'exécution similaire, ce qui est troublant (cf. corrigé de la question suivante).
---endCorr
Question 3
Dans cette question, au vu du comportement de nonAlign, on cherche à comprendre pourquoi, par défaut, le compilateur cherche à avoir les feuilles des structures alignées sur des frontières de 4 octets.Pour ce faire, il faut étudier la traduction assembleur de l'instruction :
t[i].unInt = UNEVALEURQUELCONQUE;Rechercher dans align.s, nonAlign.s et nonAlignPacked.s l'instruction assembleur correspondant à l'instruction C ci-dessus (au fait, quelle instruction du Makefile a généré l'assembleur ?).
Au vu de la différence de performances entre align et nonAlignPacked, qu'en pensez-vous ?
---beginCorr
Les fichiers assembleurs ont été générés par la commande (dans le Makefile) :
${CC} -S
nomFichier.cPar exemple, on peut les retrouver en faisant :
$ grep
1234567890
*.s
align.s:
movl $1234567890, (%edx,%eax)
nonAlignPacked.s:
movl $1234567890, 2(%edx,%eax)
nonAlign.s:
movl $1234567890, (%edx,%eax)Les movel sont différents : on a un "
2(%edx,%eax)" pour nonAlignPacked.s
alors
qu'on a "(%edx,%eax)" pour
les
autres. Ce 2 signifie, en fait, décalage de 2 octets par rapport
à
la frontière de 4 octets (NB : si dans la structure
tableElement,
on avait eu un char, puis un int (au lieu d'un short, puis un int,
comme
actuellement), on aurait eu un "1(%edx,%eax)".NB :
- Dans le cas de processeurs ne sachant pas stocker un entier sur une frontière de 4 octets, on aurait même eu une série d'instructions liées au fait que le processeur ne sait pas faire. Ce travail permet de mieux comprendre le travail effectué par le Pentium ou le 68K de manière cachée :
- Shift de 16 bits pour que les octets de poids fort se retrouvent en poids faible.
- Stockage de ce "short"
- Shift de 16 bits pour que les octets de poids faible se retrouvent en poids fort.
- Stockage de ce "short"
- C'est pourquoi certains compilateurs (par exemple,
microtech) réagissent
dans ce genre de situations en signalant "WARNING : inefficient
alignment").
---endCorr
Question 4
Dans la question 3, on a observé que align et nonAlignPacked avaient des performances similaires. Dans cette question, on va montrer que si on est sur une frontière de 16 octets (liée aux instructions MMX, cf. exercice 8), nonAlignPacked est légèrement moins performant que align.Analyser le fichier testAlign.c. Que fait-il ?
Exécuter plusieurs fois testAlign.
Dans le Makefile, supprimer -DALIGN, sauvegarder et taper la commande :
makeExécuter plusieurs fois testAlign.
Commenter les différences de performance observées
---beginCorr
testAlign.c accède de nombreuses fois à un entier dans un élément de tableau. Quand le flag de compilation ALIGN est positionné (respectivement non positionné), cet entier est juste avant (respectivement à cheval sur) une frontière de 16 octets. Le fonctionnement du programme correspond alors à align (respectivement nonAlignPacked).
Lors du fonctionnement comme align (respectivement nonAlignPacked), on observe un temps de 6,47 us par accès (respectivement 6,67 us), doit un écart de 0,20 us (soit un écart de 3,1%). Aucun doute, les ingénieurs d'Intel ont bien travaillé pour que leurs processeurs soient peu sensibles aux problèmes d'alignement sur des frontières de 16 octets.
---endCorr
Question 5
Quelle règle de programmation pouvez-vous vous fixer par rapport
aux
structures ?---beginCorr
Il faut aligner les feuilles sur des frontières de 4 octets en réordonnançant des feuilles de manières à combler les trous (et éviter des pertes de mémoire pour les structures non compressées et les pertes de performance pour les structures compressées).
---endCorr
Exercice 4 : Algorithme des "frères siamois" (Buddy System)
Soit un système utilisant l'agorithme des frères siamois pour gérer la mémoire. Initialement, la mémoire consiste en un bloc de 256K.- Représenter l'état d'occupation de la mémoire après les placements successifs des processus A(5K), B(25K), C(35K), et D(20K) puis les terminaisons successives des processus dans l'ordre A, D, C, et B.
- Initialement : 256
- Création de A (5K) : A=8 8 16 32 64 128
- Création de B (25K) : A=8 8 16 B=32 64 128
- Création de C (35K) : A=8 8 16 B=32 C=64 128
- Création de D (20K) : A=8 8 16 B=32 C=64 D=32 32 64
- Fin de A : 32 B=32 C=64 D=32 32 64
- Fin de D : 32 B=32 C=64 128
- Fin de C : 32 B=32 64 128
- Fin de B : 256
Exercice 5 : Allocation avec le Buddy System
Soit un système utilisant l'algorithme des frères siamois pour gérer la mémoire.- Ecrire de façon schématique la procédure allocation(T) qui correspond à une demande d'allocation d'une zone mémoire de taille T et dont la réponse est soit l'adresse du buddy alloué, soit -1 si l'allocation est impossible.
On suppose que le système gère une liste pour chaque puissance de i utilisée et on ne demande pas de détailler la gestion de cette liste (on se limitera à écrire par exemple "insérer l'élément dans la liste i").
allocation(T)---endCorr
début
| calcul de i tel que 2^(i-1) < T <= 2^i
| adr=trouver_trou( 2^i )
| retour (adr)
fintrouver_trou ( 2^i )
début
| si (i > max) alors
| | retour -1 /* allocation impossible T > taille mémoire */
| fin_de_si
| si (liste(i) vide) alors
| | ad=trouver_trou( 2^(i+1))
| | si (ad <> -1) alors
| | | diviser ce trou en 2 trous 2^i
| | | placer ces 2 trous 2^i dans la liste (i)
| | sinon
| | | retour ( -1 )
| | fin_de_si
| fin_de_si
| adresse_trou = extraire_1er_trou_liste (i)
| retour adresse_trou
fin
Exercice 6 : Anomalie de Belady
On appelle "anomalie de Belady" le fait que le nombre de défauts de pages augmente quand on augmente le nombre de cadres de pages disponibles.On appelle "algorithme à pile" un algorithme présentant la propriété d'inclusion : c'est-à-dire, S(N,C) inclus dans S(N+1,C) quelle que soit la chaîne de références de pages C. S(N,C) représente l'ensemble des pages présentes en mémoire après traitement de la chaîne C lorsque l'on dispose de N cadres de page.
Une condition suffisante pour qu'un algorithme ne présente pas l'anomalie de Belady est qu'il soit à pile.
- Montrer que LRU est à pile.
- Montrer l'anomalie de Belady avec l'algorithme FIFO avec N=3 puis N=4, sur l'exemple suivant : C = { 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5 }.
Retrouver sur cet exemple des états pour lesquels la propriété d'inclusion n'est pas vérifiée.
- Pour l'algorithme LRU, avec n cadres de pages, les n pages en mémoire sont les n dernières pages référencées.
- Avec 3 cadres de pages :
Il est alors évident que les k+1 pages en mémoire qui sont les k+1 dernières pages référencées contiennent toujours les k dernières pages référencées.
Exemple : soit la chaîne : 1 3 5 1 4 2 4 3.
Avec 3 cadres de pages, on a en mémoire les ensembles successifs : {1}, {1 3}, {1 3 5}, {1 3 5}, {1 5 4}, {1 4 2}, {1 4 2}, et {4 2 3}.
Avec 4 cadres de pages, on a en mémoire les ensembles successifs : {1}, {1 3}, {1 3 5}, {1 3 5}, {1 3 5 4}, {1 5 4 2}, {1 5 4 2}, et {1 4 2 3}.
On constate que chaque ensemble avec 3 cadres est toujours inclus dans son homologue avec 4 cadres de pages.
-
Page référencée :
1 2 3 4
1 2 5 1 2 3 4 5
Cadre 0 : 1 1 1 4 4 4 5 5 5 5 5 5
Cadre 1 : - 2 2 2 1 1 1 1 1 3 3 3
Cadre 2 : - - 3 3 3 2 2 2 2 2 4 4
Nombre de défauts : 1 2 3 4 5 6 7 7 7 8 9 9
-
Page référencée :
1 2 3 4
1 2 5 1 2 3 4 5
Cadre 0 : 1 1 1 1 1 1 5 5 5 5 4 4
Cadre 1 : - 2 2 2 2 2 2 1 1 1 1 5
Cadre 2 : - - 3 3 3 3 3 3 2 2 2 2
Cadre 3 : - - - 4 4 4 4 4 4 3 3 3
Nombre de défauts : 1 2 3 4 4 4 5 6 7 8 9 10
On peut noter que lors du premier chargement de la page 5, l'ensemble des pages en mémoire avec 3 cadres : {5 1 2}, n'est pas inclus dans l'ensemble obtenu avec 4 cadres : {5 2 3 4}.
On a la même situation avec {5 1 2} non inclus dans { 5 1 3 4 } et { 5 3 4 } non inclus dans {4 1 2 3 }.
Exercice 7 : Profiling d'un allocateur "maison"
Préparation
Placez-vous dans un répertoire de travailtar xvfz cmpAlloc.tgz
cd CmpAlloc
Question 1
Complétez les parties "/* A completer */" dans le fichier monAllocateur.cNB : Ne vous occupez pas, pour l'instant, des "* A completer au moment de la question 2 *". Vous vous en occuperez... au moment de la question 2.
Tapez make pour le compiler
---beginCorr
monAllocateur.corrige.c
---endCorr
Question 2
Exécutez le programme "bug". La troisième ligne qu'il affiche signale un bug :s1 = "1234567890123456"
s2 = "" ==> BUG !
Exécutez : valgrind ./bug
Valgrind ne détecte aucun problème.
Dans monAllocateur.c, complétez les "* A completer au moment de la question 2 *" pour expliquer : a. l'origine de ce bug, b. la raison pour laquelle valgrind utilisé sur le programme bug ne détecte rien, et enfin c. quelle fonction utilisée en lieu et place de strcpy aurait évité ce bug.
---beginCorr
- a. La constante CHAINE de bug.c fait 16 caractères. Elle occupe donc 17 octets en mémoire avec le '\0' final. De ce fait, quand on affecte CHAINE à s1, le '\0' de s1 déborde sur le premier octet de s2. s2 se retrouve donc avec la valeur "".
- b. Valgrind ne détecte rien, car toutes ces opérations se déroulent dans une zone mémoire de NBMAXALLOC*TAILLEBLOC=48 octets alloués au moment de l'exécution de monAllocateurInit(). Donc, nous ne dépassons pas les bornes de cette zone mémoire. Pour information, si vous mettez 2 comme valeur de NBMAXALLOC et que vous recompilez, valgrind détecte le problème dès le strcpy sur s2 !
- c. L'utilisation de strncpy(s1s2,
CHAINE, TAILLEBLOC) nous aurait évité ce bug.
Question 3
Exécutez ./cmpAlloc
100000000 1Tapez gprof cmpAlloc
Les premières lignes vous indiquent le temps cumulé passé dans chaque fonction. Par exemple, nous avons obtenu l'affichage suivant sur une machine Dell Precision T3500 computers, équipée d'un processeur Intel Xeon W3530 (2.80 GHz) et de 4 GiB of RAM, avec un système d'exploitation Linux 3.14.9 SMP :
% cumulative self self total
time seconds seconds calls s/call s/call name
50.21 2.06 2.06 1 2.06 2.06 travailAvecMalloc
44.58 3.89 1.83 1 1.83 2.05 travailAvecMonMalloc
2.82 4.00 0.12 50000001 0.00 0.00 monFree
2.69 4.11 0.11 50000001 0.00 0.00 monMalloc
0.12 4.12 0.01 1 0.01 0.01 monAllocateurInit
gprof nous indique qu'avec un total de 2,06 secondes, travailAvecMalloc est aussi performant que travailAvecMonMalloc qui requiert un total de 2,05 secondes. Ce résultat contre-intuitif est dû au fait que les fonctions malloc et free n'ont pas été prises en compte ! Pour qu'elles soient prises en compte, il faut faire une édition de lien avec la version profilée de la bibliothèque standard C. Donc :
- Editez le Makefile
- Modifiez la ligne concernant LDFLAGS avec : LDFLAGS = -pg -static -lc_p
- make cleanall ; make
2 cas peuvent se présenter : - Vous n'avez pas d'erreur à l'édition de liens : passez au point 4.
- Vous avez une erreur "/usr/bin/ld: ne peut trouver -lc_p" : la version profilée de la bibliothèque C n'est pas installée sur votre système. Nous supposons que vous n'avez pas les droits root sur la machine que vous utilisez. Nous allons donc mettre en oeuvre un moyen d'obtenir cette version profilée de bibliothèque sans avoir besoin de l'installer :
- cd /tmp
- Récupérez une version récente de la bibliothèque C de GNU : wget http://ftp.gnu.org/gnu/glibc/glibc-2.21.tar.gz
- tar xvfz glibc-2.21.tar.gz
- mkdir glibc-build
- cd glibc-build
- ../glibc-2.21/configure --prefix=$HOME/Software/glibc --enable-profile
- Si cette commande vous affiche :
configure: error:
tapez : export LD_LIBRARY_PATH=
*** LD_LIBRARY_PATH shouldn't contain the current directory when
*** building glibc. Please change the environment variable
*** and run configure again.
puis : ../glibc-2.21/configure --prefix=$HOME/Software/glibc-2.21 --enable-profile - make # Comptez environ 15 minutes de compilation
- make install
- Revenez dans le répertoire CmpAlloc
- Editez le makefile
- Modifiez la ligne concernant LDFLAGS avec : LDFLAGS = -pg -static -L${HOME}/Software/glibc-2.21/lib -lc_p
- make cleanall;make
- Exécutez ./cmpAlloc 100000000 1
- Tapez gprof cmpAlloc
Livrez votre fichier monAllocateur.c final selon les modalités qui vous ont été indiquées.
---beginCorr
monAllocateur.corrige.c
---endCorr
Exercice 8 : Contraintes et gains liés aux instructions MMX/SSE
Préparation
Se placer dans un répertoire de travailtar xvfz instructionsSSE.tgz
cd InstructionsSSE
Question 1
Le fonctioncomputeResult
du programme calculV0.c
réalise des calculs
sur les éléments de deux tableaux de flottants pArray1 et pArray2 de
taille SIZE. Le
résultat est stocké dans pResult.On se propose d'accélérer l'exécution de ce programme en utilisant les instructions SSE du processeur Intel pour faire les calculs 4 flottants par 4 flottants.
SSE est :
- une collection de registres de 128 bits,
- un jeu d'instructions qui permet de voir ces registres comme 4 éléments (entier, flottant) de 32 bits et faire des opérations sur ces 4 entiers simultanément. On peut accéder aux instructions SSE soit en programmant directement en assembleur, soit en utilisant des fonctions intrinsèques (intrinsics), c'est-à-dire des fonctions que le compilateur sait directement traduire en une (ou plusieurs) instruction(s) assembleur (voir http://neilkemp.us/src/sse_tutorial/sse_tutorial.html pour plus d'informations).
calculV1.c (respectivement calculV2.c)
est une version de calculV0.c
exploitant des instructions SSE. Il travaille sur des tableaux
alloués
statiquement (respectivement dynamiquement). Vérifier que le Makefile
prend en compte le commentaire en tête de calculV1.c et calculV2.c.Taper make pour compiler tous ces programmes.
Taper
/usr/bin/time calculV0Exécuter
calculV1
et calculV2 (sans /usr/bin/time). Pourquoi est-ce
que ces deux programmes
plantent ?---beginCorr
calculV1 et calculV2 plantent, car les
tableaux ne sont pas alignés sur
des frontières de 16 octets. De ce fait, le processeur n'arrive
pas à
charger dans ses registres les groupes de 4 flottants. Ce
problème
disparaîtra avec le jeu d'instructions AVX qu'a annoncé
Intel.---endCorr
Question 2
CorrigercalculV1.c et calculV2.c pour qu'ils ne
plantent plus.---beginCorr
calculV1.corrige.c
calculV2.corrige.c
---endCorr
Taper
/usr/bin/time calculV1Taper
/usr/bin/time calculV2Calculer le gain de performances obtenu par rapport à celles de
calculV0. Commenter.---beginCorr
Sur la machine anaconda,
calculV0
(respectivement calculV1
et calculV2)
s'exécute en 0,29 s (respectivement 0,07 s et 0,07 s). On a donc
un
gain de près de 75% en temps d'exécution. C'ets logique
dans la mesure
où le gros du temps d'exécution est
représenté par les calculs sur les flottants. Or,
avec ce programme, on fait 4 calculs en parallèle, d'où
le gain d'un
facteur 4 (75%) en temps d'exécution.---endCorr
NB : Quelques liens pour approfondir :
- http://www.codeproject.com/KB/recipes/sseintro.aspx contient le code dont est inspiré cet exercice.
- http://bmagic.sourceforge.net/bmsse2opt.html présente l'utilisation des instructions SSE pour les opérations aouur tdes bis (par exemple, nombre de bits à 1 dns un registre).
- http://www.cortstratton.org/articles/OptimizingForSSE.php est un article présentant une démarche d'optimisation de multiplication de 2 matrices.
- Intel AVX est une extension de SSE à base de registres 256 bits, sans problèmes d'alignement. Il est offert depuis 2010 sur la famille de processeurs Sandy Bridge.
- Les processeurs ARM ont également des instructions qui permettent de gagner en efficacité. Voir ces spécificités en http://en.wikipedia.org/wiki/ARM_architecture#Instruction_set.
Exercice 9 : Arbre AVL
Un arbre AVL (arbre de Georgy Adelson-Velsky et Landis, nommé d'après ses inventeurs) est un arbre binaire de recherche qui s'auto-équilibre. Dans un arbre AVL, la hauteur de deux arbres enfant d'un nœud quelconque diffère d'au plus 1. Si à un moment, leur hauteur diffère de plus de un, un rééquilibrage est déclenché.Cela garantit une vitesse de recherche dans l'arbre qui est en log2(n), n étant le nombre de nœuds.
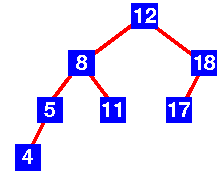
Par exemple, l'arbre de la figure 1 est un arbre AVL, car, pour chaque nœud, la différence de hauteur entre le sous-arbre de gauche et le sous-arbre de droite est inférieure ou égale à 1.
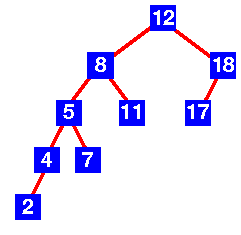
En revanche, l'arbre de la figure 2 n'est pas un arbre AVL. En effet, pour le nœud 12, la hauteur du sous-arbre de gauche est 4, tandis que la hauteur du sous-arbre de droite est 2.
Dans cet exercice, vous allez coder un arbre AVL que nous utiliserons pour stocker des paires clé/valeur comme le font les classes Dictionnary de Java et std::map de la STL C++.
Remarque préliminaire
Vous devez veiller à ce que :- votre code compile sans warning ;
- dans votre code, quand vous libérez une zone mémoire, vous mettez le pointeur sur cette zone mémoire à NULL.
Préparation
Se placer dans un répertoire de travailtar xvfz arbreAVL.tgz
cd ArbreAVL
mv arbreAVL.c arbreAVL_$USER.c
mv testsUnitaires.c testsUnitaires_$USER.c
Cet exercice s'appuie sur un environnement de tests unitaires appelé cmocka. Vous allez l'installer pour pouvoir vous en servir..
Téléchargez l'archive contenant la dernière version de cmoka (à l'heure où nous écrivons cet énoncé, cette archive s'appelle cmocka-1.1.1.tar.xz). Dans le terminal dans lequel vous avez effectué les opérations précédentes :
tar xvfz cmocka-*.tar.xz
mv cmocka-* cmocka
cd cmocka
mkdir build
cd build
cmake -DCMAKE_INSTALL_PREFIX=../install -DCMAKE_BUILD_TYPE=Debug ..
make
make install # Ca y est : cmocka est installe
cd ../.. # Vous etes revenu.e. dans le repertoire ou vous allez faire votre exercice
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:cmocka/install/lib
Question 1 : Amélioration des tests unitaires
Cet exercice est fait selon la méthode TDD (Test Driven Development). L'odée est d'écrire complètement les tests de votre module dans testsUnitaires_usernameUnix.c, avant de passer au codage de votre module dans arbreAVL_usernameUnix.c.Dans le fichier testsUnitaires_usernameUnix.c, en vous inspirant du code déjà existant, remplacez les lignes signalées par un TODO par un appel à assert_null() ou assert_int_equal() pour tester le cas où l'une des fonctions offertes par arbreAVL_usernameUnix.c est appelée avec un arbre AVL vide (i.e. le paramètre vaut NULL).
Dans votre terminal, tapez make run pour compiler votre code et l'exécuter. Sans surprise, tous les tests échouent.
NB :
- La compilation génère le warning "arbreAVL_usernameUnix.c:57:21: warning: ‘newNode’ defined but not used [-Wunused-function] static struct Node* newNode(const char *key)". Vu que vous n'avez pas encore commencé à coder arbreAVL_usernameUnix.c, ce warning est acceptable. Les warnings de compilation ne seront plus acceptés à partir de la question suivante.
- Si la commande make run affiche le message "./testsUnitaires:
error while loading shared libraries: libcmocka.so.0: cannot open
shared object file: No such file or directory", dans votre terminal, tapez la commande :
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:cmocka/install/lib
---beginCorr
testsUnitaires.corrige.c
Barème concernant la qualité de l'ensemble du code
- 1 pt : 0 warning à la compilation
- 1 pt : valgrind ne signale aucune erreur (0,5 pt = aucune erreur d'accès et 0,5 pt pour absence de fuites mémoire)
- - 2 pt : pénalité pour livraison non conforme
au format demandé (sanction sévère, mais il semble
difficile de ne pas être conforme)
- 2 pt : à raison de 0,4 pt par test à coder (nbNode() quand root==NULL, idem pour release(), getKeyHeight(), getKeyRank(), getValue())
Question 2 : Codage des fonctions update_height(), nbNodes(), newNode(), insert() et release()
Dans arbreAVL_usernameUnix.c, complétez tous les TODO des fonctions updateHeight(), nbNodes(), newNode() et insert(). Ne vous occupez pas de release() pour l'instant.NB : Ne vous préoccupez pas pour l'instant de construire un arbre équilibré (la fonction
insert
ne
réalise donc pas, pour l'instant, d'auto-équilibrage) ou
du stockage de la valeur associée à chaque clé.
Aussi, votre fonction insert doit travailler de la
manière suivante :- Si
nodevautNULL,insertrenvoienewNode(key) - Si
keyest plus petit quenode->key,insertinsèrekeydans une feuille la plus basse possible du sous-arbre de gauche denode.
Pour ce faire, nous vous recommandons d'appeler récursivementinsert. NB : la fonction insert() renvoie un struct node *. Aussi, n'oubliez pas de stocker le noeud renvoyé par insert() dans votre structure de données (ne vous contentez pas d'appeler insert() sans tenir compte de sa valeur de retour, dit autrement comme si c'était une procédure ; vous auriez alors probablement des bugs à cette question ou aux questions suivantes).
- Si
keyest plus grand quenode->key, insert insèrekeydans une feuille la plus basse possible du sous-arbre de droite denode.
Pour ce faire, nous vous recommandons d'appeler récursivementinsert. Même NB qu'au point précédent.
- Si
keyest égal ànode->key,insertrenvoie simplementnodesans rien faire d'autre (ainsi, il n'y jamais deux valeurs identiques dans l'arbre). - Puis,
insertmet à jour le champheightdenode.
[ OK ] test_insert_et_nbNode
Exécutez maintenant valgrind ./testsUnitaires. Valgrind vous signale au minimum que vous avez des fuites mémoires. Complétez release() et éventuellement les autres fonctions codées jusqu'à présent pour que valgrind ./testsUnitaires ne vous signale aucun problème d'accès mémoire ou de fuite mémoire.
Ainsi, test_insert_et_nbNode et test_release sont OK.
---beginCorr
arbreAVL.corrige.c
Barème :
- 0,5 pt : codage correct de updateHeight()
- 1,5 pt : codage correct de newNode(), 0,5 pt pour malloc (pour node et pour key), 0,25 pour strcpy de key, 0,5 pt pour le fait que le code retour de malloc est testé, 0,25 pt pour initialisation correcte champs left, right et height
- 1,5 pt : codage correct de insert()
- 1,5 pt : codage correct de release(), dont 0,75 pt pour la remise à NULL de node->left, node->right, node->key
- 1 pt : codage correct de nbNode()
Question 3 : Codage des fonctions getKeyHeight() et getKeyRank()
Codez getKeyHeight() jusqu'à ce que test_getKeyHeight soit OK. N'oubliez pas de vérifier avec valgrind que vous n'avez aucun soucis d'accès mémoire ou de fuite mémoire.Codez getKeyRank() jusqu'à ce que test_getKeyRank soit OK.
---beginCorr
arbreAVL.corrige.c
Barème :
- 1 pt : codage correct de getKeyHeight()(NB : 0,5 pt pour la qualité de l'algorithme, notamment le fait que le code cherche la clé dans le bon sous-arbre)
- 2 pt : codage correct de getKeyRank() (2 pt, car cet algorithme est difficile)
Question 4 : Mise à jour du code pour équilibrer l'arbre au moment de sa construction
Cette question a pour objectif de travailler à
l'équilibrage de l'arbre au moment de sa construction.Pour ce faire, une fois l'insertion réalisée, pour chacun des nœuds concernés par l'insertion, il faut calculer sa "balance", i.e. la différence de hauteur entre le sous-arbre gauche du nœud et son sous-arbre droit.
Si la balance d'un nœud est comprise entre -1 et +1, il n'y a rien à faire.
En revanche, si la balance d'un nœud est strictement inférieure à -1 ou strictement supérieure à +1, il faut rééquilibrer l'arbre au niveau de ce nœud. 4 cas se présentent (à traiter dans la fonction
insert()
après le calcul de la balance). Dans la présentation de
ces 4 cas, 3 nœuds jouent un rôle particulier :- z est le nœud le plus profond au niveau duquel la
balance est strictement inférieure à -1 ou
strictement supérieure à +1 ;
- x est le nœud petit-enfant de z, dont l'arbre
contient la clé qui vient d'être insérée ;
- y est le nœud enfant de z, qui est parent de x.
2ème cas - Cas Droite-Droite : Au niveau de z, l'arbre est déséquilibré à droite. De plus, x est situé à droite de y. Alors, pour rééquilibrer l'arbre, il suffit d'effectuer une rotation gauche de z (cf. figure 4).
3ème cas - Cas Gauche-Droite : Au niveau de z, l'arbre est déséquilibré à gauche. De plus, x est situé à droite de y. Alors, pour rééquilibrer l'arbre, il suffit d'effectuer une rotation gauche de y, puis une rotation droite de z (cf. figure 5).
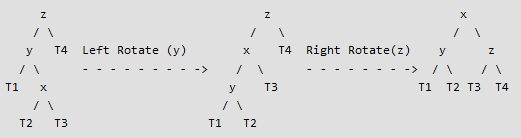
4ème cas - Cas Droite-Gauche : Au niveau de z, l'arbre est déséquilibré à droite. De plus, x est situé à gauche de y. Alors, pour rééquilibrer l'arbre, il suffit d'effectuer une rotation droite de y, puis une rotation gauche de z (cf. figure 6).

Gérer ces 4 cas pour ce nœud suffit à rééquilibrer l'arbre entier, car l'arbre retrouve sa hauteur d'origine.
Complétez arbreAVL_usernameUnix.c :
- codez
la fonction
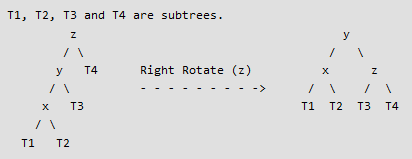
static struct Node *rightRotate(struct Node *z)qui réalise le traitement présenté à la figure 3 et retourne la nouvelle racine du sous arbre (ici,y); par ailleurs, cette fonction modifie le champheightdes nœuds y et z ;
- codez la fonction
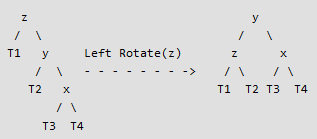
static struct Node *leftRotate(struct Node *z)qui réalise le traitement présenté à la figure 4 et retourne la nouvelle racine du sous-arbre (iciy); par ailleurs, cette fonction modifie le champheightdes nœuds y et z ; - ajoutez le calcul de la
balance et le traitement des 4 cas à la fonction insert().
- les tests test_equilibrageGaucheGauche, test_equilibrageDroiteDroite, test_equilibrageGaucheDroite et test_equilibrageDroiteGauche soient OK ;
- valgrind ./testsUnitaires ne vous signale aucun problème d'accès mémoire ou de fuite mémoire.
---beginCorrarbreAVL.corrige.c
Barème :
- 0,75 pt : Codage correct de rightRotate()
- 0,75 pt : Codage correct de lefttRotate()
- 0,5 pt : Calcul correct de la balance
- 2 pt : Traitement des 4 cas
Question 5 : Stockage de paires clé/valeur dans l'arbre AVL
Jusqu'à présent, notre arbre AVL n'a servi qu'à stocker des clés. Cette question a pour objectif d'utiliser cet arbre pour y stocker des paires clé/valeur, et ainsi obtenir une structure de données de type dictionnaire (cf. classes Dictionnary de Java et std::map de la STL C++) nous permettant de retrouver la valeur associée à une clé avec une complexité en O(log(n)).Complétez arbreAVL.h et arbreAVL_usernameUnix.c :
- ajoutez un champ
char *valueà la structureNode; - ajoutez un paramètre
char *valueà la fonctionnewNodeet recopiez le dans le champvaluedu nœud créé à l'aide de ce paramètre ; - ajoutez un paramètre
char *valueà la fonctioninsertet utilisez ce paramètre de manière adéquate dans cette fonction. En particulier, s'il existe déjà un nœud ayant pour clékeydans l'arbre, veillez à remplacer l'ancienne valeur du champvaluede ce nœud à l'aide de ce paramètre ; - Complétez la fonction
getValue()
NB : il est probable que l'algorithme de recherche du nœud dansgetValue()ressemble à s'y méprendre à l'algorithme de recherche du nœud dansgetKeyHeight(). Pour éviter une duplication de code (jamais saine dans un projet), créez une fonction qui centralise ce code et qui est appelée pargetValue()etgetKeyHeight().
cp testsUnitaires_$USER.c /tmp # pour sauvegarder votre fichier initial
sed 's@); //@,@g' testsUnitaires_$USER.c > /tmp/toto.c
cp /tmp/toto.c testsUnitaires_$USER.c
Par précaution, vérifiez que les changements de ligne se sont bien passés en tapant
diff testsUnitaires_$USER.c /tmp/testsUnitaires_$USER.c | grep -v insert
Vous ne devez avoir que des lignes du style
---
54,58c54,58
---
cp /tmp/testsUnitaires_$USER.c .
afin de récupérer votre fichier initial. Puis, postez un message de SOS sur le forum.
Enfin, tapez make run. Corrrigez vos fonctions jusqu'à ce que :
- le test test_getValue soit OK ;
- valgrind ./testsUnitaires ne vous signale aucun problème d'accès mémoire ou de fuite mémoire.
---beginCorrarbreAVL.corrige.c
arbreAVL.corrige.h
testsUnitaires.corrige.c
NB : il existe de nombreux sites qui traitent des arbres AVL. Deux ont plus particulièrement retenu notre attention pour leur pédagogie :
- https://www.hackerrank.com/challenges/self-balancing-tree
- http://www.geeksforgeeks.org/avl-tree-set-1-insertion/
- 1 pt : Traitement correct du paramètre value dans newNode() (0,33 pt pour le malloc, 0,33 pour le test de retour du malloc, 0,33 pt pour strcpy)
- 0,5 pt : dans release(), free(node->value) et node->value = NULL (il faut faire les 2 instructions pour avoir ces 0,25 points)
- 0,5 pt : dans insert(), realloc() de node->value() quand clé avec nouvelle valeur : 0,25 pour realloc, 0,25 pour test retour realloc, 0,25 pour strcpy (NB : pas de pénalité si le code fait systématiquement realloc, sans vérifier que la valeur a changé et qu'il faut donc effectivement le faire)
- 1 pt : Codage correct de la fonction commune à
getValue()etgetKeyHeight()et appels corrects à cette fonction dansgetValue()etgetKeyHeight().
Remarque finale : il existe d'autres algorithmes qu'AVL pour obtenir des arbres binaires équilibrés. Un autre algorithme célèbre est l'arbre bicolore ou arbre rouge-noir (en anglais : red-black tree). C'est d'ailleurs ce dernier qui est utilisé dans les classes Dictionnary de Java et std::map de la STL C++. Pour le langage C, http://libredblack.sourceforge.net/ en propose une implémentation utilisable pour tout type de données. N'hésitez pas à vous en servir plutôt que de réinventer la roue !
Livraison de votre travail sous Moodle
Quand vous aurez terminé votre exercice, si vous souhaitez faire
remonter des remarques au correcteur de votre travail, créez un
fichier readme.txt dans le répertoire où se trouve votre
travail et notez dans ce fichier vos remarques.Tapez ensuite la commande : make gentgz
2 cas peuvent se présenter :
- Cas 1 : Cette commande affiche le message "===> OK, fichier arbreAVL_usernameUnix.tgz genere : vous pouvez le remonter dans Moodle."
La génération du fichier d'archive arbreAVL_usernameUnix.tgz s'est bien passée. Il ne vous reste plus qu'à remonter ce fichier dans Moodle. - Cas 2 : cette commande affiche le message "make:
*** Aucune règle pour fabriquer la cible
« arbreAVL_usernameUnix.c », nécessaire pour
« gentgz ». Arrêt." (et/ou le même message concernant testsUnitaires_usernameUnix.c). Cela signifie que vous avez oublier de taper la commande cp arbreAVL.c arbreAVL_$USER.c (et/ou la commande cp concernant testsUnitaires.c) dans la phase préliminaire de cet exercice. Faites-le(s), puis tapez à nouveau make gentgz